Los últimos diez años han sido testigos de avances masivos en las áreas de computación. La primera es que el hardware se ha ido abaratando cada vez más, y a su vez se ha ido haciendo más potente: las computadoras de sobremesa hoy en día tienen la potencia que poseían los mainframes hace algunos años. La segunda área es la de las comunicaciones; avances tales como los sistemas de comunicación vía satélite y los sistemas de teléfonos digitales significa que ahora es posible conectar económicamente y eficientemente con otros sistemas informáticos separados físicamente. Esto ha llevado al concepto de un sistema de computación distribuido. Dicho sistema consiste en un número de computadoras que están conectadas y que llevan a cabo diferentes funciones. Existen muchas razones por las que tales sistemas se han hecho populares:
Rendimiento. El rendimiento de muchos tipos de sistemas distribuidos se puede incrementar añadiendo simplemente más computadoras. Normalmente esta es una opción más sencilla y más barata que mejorar un procesador en un mainframe. Los sistemas típicos en donde se puede lograr este incremento en el rendimiento son aquellos en donde las computadoras distribuidas llevan a cabo mucho proceso, y en donde la relación trabajo de comunicaciones y proceso es bajo.
Compartición de recursos. Un sistema distribuido permite a sus usuarios acceder a grandes cantidades de datos que contienen las computadoras que componen el sistema. En lugar de tener que reproducir los datos en todas las computadoras se pueden distribuir por un pequeño número de computadoras. Un sistema distribuido también proporciona acceso a servicios especializados que quizás no se requieran muy frecuentemente, y que se puedan centralizar en una computadora del sistema.
Tolerancia a fallos. Un sistema distribuido se puede diseñar de forma que tolere los fallos tanto del hardware como del software. Por ejemplo, se pueden utilizar varias computadoras que lleven a cabo la misma tarea en un sistema distribuido. Si una de las computadoras funcionaba mal, entonces una de sus hermanas puede hacerse cargo de su trabajo. Una base de datos de una computadora se puede reproducir en otras computadoras de forma que si la computadora original tiene un mal funcionamiento, los usuarios que solicitan la base de datos son capaces de acceder a las bases de datos reproducidas.
A. Sistemas distribuidos
Clientes y Servidores
El propósito de esta sección es introducir tanto la idea de cliente como la de servidor. Estos son los bloques básicos de construcción de un sistema distribuido y, de esta manera, cuando se describa el diseño y el desarrollo de dichos sistemas, será necesario tener conocimiento de sus funciones y de su capacidad.
Un servidor es una computadora que lleva a cabo el propósito de esta sección es introducir tanto la idea de cliente como la de servidor. Estos son los bloques básicos de construcción de un sistema distribuido y, de esta manera, cuando se describa el diseño y el desarrollo de dichos sistemas, será necesario tener conocimiento de sus funciones y de su capacidad.
Un servidor es una computadora que lleva a cabo un servicio que normalmente requiere mucha potencia de procesamiento. Un cliente es una computadora que solicita los servicios que proporciona uno o más servidores y que también lleva a cabo algún tipo de procesamiento por sí mismo. Esta forma de organización de computadoras es totalmente diferente a los dos modelos que dominaron los años ochenta y principios de los noventa.
El primer modelo se conoce como procesamiento central (host). En este modelo de organización todo el procesamiento que se necesitaba para una organización se llevaba a cabo por una computadora grande –normalmente una mainframe- mientras que los usuarios emplean sencillas terminales informáticas o PCs de muy poca potencia para comunicarse con el central. Los dos problemas más serios son la dificultad de mejorar y de copiar con interfaces IGU modernas. A medida que las aplicaciones van siendo más grandes, la carga de una mainframe común llega al punto en que también necesita mejorar y normalmente con hardware de procesamiento nuevo, memoria o almacenamiento de archivos. Mejorar dichas computadoras es más fácil que antes; sin embargo, puede resultar un proceso moderadamente difícil y caro es ciertamente más caro y más difícil que añadir un servidor nuevo basado en PC a un conjunto de computadoras configuradas como clientes y servidores. El segundo problema es hacerse con interfaces IGU modernas. Para ordenar a una computadora que visualice incluso una pantalla relativamente primitiva relacionada, digamos, con unos cuantos botones y una barra de desplazamiento de la misma, conlleva tanto tráfico en las líneas de comunicación que un sistema podría colapsarse fácilmente con los datos que se utilizan para configurar y mantener una serie de interfaces basadas en IGUs.
El segundo modelo de computación es en donde hay un grupo de computadoras actuando como servidores, pero poseen poco procesamiento que llevar a cabo. Normalmente estos terminales poco inteligentes actuarían como servidores de archivos o servidores de impresión para un número de PCs potentes o minicomputadoras que llevarían a cabo el procesamiento y estarían conectados a una red de área local. Las computadoras cliente solicitarían servicios a gran escala, como es obtener un archivo, llevando a cabo entonces el procesamiento de dicho archivo. De nuevo, esto conduce a problemas con el tráfico en donde, por ejemplo, la transmisión de archivos grandes a un número de clientes que requieren simultáneamente estos archivos hace que el tiempo de respuesta de la red vaya tan lento como una tortuga.
La computación cliente/servidor es un intento de equilibrar el proceso de una red hasta que se comparta la potencia de procesamiento entre computadoras que llevan a cabo servicios especializados tales como acceder a bases de datos (servidores), y aquellos que llevan a cabo tareas tales como la visualización IGU que es más adecuado para el punto final dentro de la red. Por ejemplo, permite que las computadoras se ajusten a tareas especializadas tales como el procesamiento de bases de datos en donde se utilizan hardware y software de propósito especial para proporcionar un procesamiento rápido de la base de datos comparado con el hardware que se encuentra en las mainframes que tienen que enfrentarse con una gran gama de aplicaciones.
Categorías de Servidores
Ya se ha desarrollado una gran variedad de servidores. La siguiente lista ampliada se ha extraído de:
Servidores de archivos. Un servidor de archivos proporciona archivos para clientes. Estos servidores se utilizan todavía en algunas aplicaciones donde los clientes requieren un procesamiento complicado fuera del rango normal de procesamiento que se puede encontrar en bases de datos comerciales. Por ejemplo, una aplicación que requiera el almacenamiento y acceso a dibujos técnicos, digamos que para una empresa de fabricación, utilizaría un servidor de archivos para almacenar y proporcionar los dibujos a los clientes. Tales clientes, por ejemplo, serían utilizados por ingenieros quienes llevarían a cabo operaciones con dibujos, operaciones que serían demasiado caras de soportar, utilizando una computadora central potente. Si los archivos solicitados no fueran demasiado grandes y no estuvieran compartidos por un número tan grande de usuarios, un servidor de archivos sería una forma excelente de almacenar y procesar archivos.
Servidores de bases de datos. Los servidores de bases de datos son computadoras que almacenan grandes colecciones de datos estructurados. Por ejemplo, un banco utilizaría un servidor de bases de datos para almacenar registros de clientes que contienen datos del nombre de cuenta, nombre del titular de la cuenta, saldo actual de la cuenta y límite de descubierto de la cuenta. Una de las características de las bases de datos que invalidan la utilización de los servidores de archivos es que los archivos que se crean son enormes y ralentizan el tráfico si se transfirieran en bloque al cliente. Afortunadamente, para la gran mayoría de aplicaciones no se requiere dicha transferencia; por ejemplo en una aplicación bancaria las consultas típicas que se realizarían en una base de datos bancaria serían las siguientes:
- Encontrar las cuentas de los clientes que tienen un descubierto mayor de 2.000 pts.
- Encontrar el saldo de todas las cuentas del titular John Smith.
- Encontrar todas las órdenes regulares del cliente Jean Smith.
- Encontrar el total de las transacciones que se realizaron ayer en la sucursal de Manchester Picadilly.
Actualmente una base de datos bancaria típica tendrá millones de registros, sin embargo, las consultas anteriores conllevarían transferir datos a un cliente que sería solamente una fracción muy pequeña del tamaño. En un entorno de bases de datos cliente-servidor los clientes envían las consultas a la base de datos, normalmente utilizando alguna IGU. Estas consultas se envían al servidor en un lenguaje llamado SQL (Lenguaje de Consultas Estructurado). El servidor de bases de datos lee el código SQL, lo interpreta y, a continuación, lo visualiza en algún objeto HCI tal como una caja de texto. El punto clave aquí es que el servidor de bases de datos lleva a cabo todo el procesamiento, donde el cliente lleva a cabo los procesos de extraer una consulta de algún objeto de entrada, tal como un campo de texto, enviar la consulta y visualizar la respuesta del servidor de la base de datos en algún objeto de salida, tal como un cuadro de desplazamiento.
Servidores de software de grupo. Software de grupo es el término que se utiliza para describir el software que organiza el trabajo de un grupo de trabajadores. Un sistema de software de grupo normalmente ofrece las siguientes funciones:
- Gestionar la agenda de los individuos de un equipo de trabajo.
- Gestionar las reuniones para un equipo, por ejemplo, asegurar que todos los miembros de un equipo que tienen que asistir a una reunión estén libres cuando se vaya a celebrar.
- Gestionar el flujo de trabajo, donde las tareas se distribuyen a los miembros del equipo y el sistema de software de grupo proporciona información sobre la finalización de la tarea y envía un recordatorio al personal que lleva a cabo las tareas.
- Gestionar el correo electrónico, por ejemplo, organizar el envío de un correo específico a los miembros de un equipo una vez terminada una tarea específica.
Un servidor de software de grupo guarda los datos que dan soporte a estas tareas, por ejemplo, almacena las listas de correos electrónicos y permite que los usuarios del sistema de software de grupo se comuniquen con él, notificándoles, por ejemplo, que se terminado una tarea o proporcionándoles una fecha de reunión en la que ciertos empleados puedan acudir.
Servidores Web. Los documentos Web se almacenan como páginas en una computadora conocida como servidor Web. Cuando se utiliza un navegador (browser) para ver las páginas Web normalmente pincha sobre el enlace en un documento Web existente. Esto dará como resultado un mensaje que se enviará al servidor Web que contiene la página. Este servidor responderá entonces enviando una página a su computadora, donde el navegador pueda visualizarlo. De esta manera los servidores Web actúan como una forma de servidor de archivos, administrando archivos relativamente pequeños a usuarios, quienes entonces utilizan un navegador para examinar estas páginas. Para comunicarse con un navegador Web, un cliente que utiliza un navegador está haciendo uso a su vez de un protocolo conocido como HTTP.
Servidores de correo. Un servidor de correo gestiona el envío y recepción de correo de un grupo de usuarios. Para este servicio normalmente se utiliza un PC de rango medio. Existen varios protocolos para el correo electrónico. Un servidor de correo estará especializado en utilizar solo uno de ellos.
Servidores de objetos. Uno de los desarrollos más excitantes en la informática distribuida durante los últimos cinco años ha sido el avance realizado, tanto por parte de los desarrolladores, como por parte de los investigadores, para proporcionar objetos distribuidos. Estos son objetos que se pueden almacenar en una computadora, normalmente un servidor, con clientes capaces de activar la funcionalidad del objeto enviando mensajes al objeto, los cuales se corresponden con métodos definidos por la clase de objeto. Esta tecnología liberará finalmente a los programadores de la programación de bajo nivel basada en protocolos requerida para acceder a otras computadoras de una red. En efecto, esto permite que el programador trate a los objetos a distancia como si estuvieran en su computadora local. Un servidor que contiene objetos que pueden accederse a distancia se conoce como servidor de objetos.
Servidores de impresión. Los servidores de impresión dan servicio a las solicitudes de un cliente remoto. Estos servidores tienden a basarse en PCs bastante baratos, y llevan a cabo las funciones limitadas de poner en cola de espera las peticiones de impresión, ordenar a la impresora que lleve a cabo el proceso de impresión e informar a las computadoras cliente que ya ha finalizado una petición de impresión en particular.
Servidores de aplicaciones. Un servidor de aplicaciones se dedica a una aplicación única. Tales servidores suelen escribirse utilizando un lenguaje tal como Java o C++. Un ejemplo típico del servidor que se utiliza en el dibujo de un fabricante de aviones que gestionaba las versiones diferentes de dibujos producidos por el personal técnico iría dirigido a algún proceso de fabricación.
Software intermedio (middleware)
Hasta el momento probablemente ya tenga la impresión de que la comunicación entre cliente y servidor es directa. Desgraciadamente, esto no es verdad: normalmente existe por lo menos una capa de software entre ellos.
Esta capa se llama software intermedio (rniddíeware). Como ejemplo de software intermedio consideremos la Figura 28.1. Ésta muestra la comunicación entre un cliente ejecutando un navegador como Internet Explorer y un servidor Web.

Aquí el software intermedio que se encuentra entre el servidor Web y el cliente que ejecuta el navegador Web intercepta las peticiones que proceden del navegador. Si se hace una petición para una página Web entonces determina la localización del documento Web y envía una petición para esa página. El servidor responde a la petición y devuelve la página al software intermedio, quien la dirige al navegador que la visualizará en la pantalla del monitor que utiliza el cliente. Existen dos categorías de software intermedio: el software intermedio general y el software intermedio de servicios. El primero es el que está asociado a los servicios generales que requieren todos los clientes y servidores. El software típico que se utiliza como tal es:
- El software para llevar a cabo comunicaciones utilizando el protocolo TCPDP y otros protocolos de red.
- El software del sistema operativo que, por ejemplo, mantiene un almacenamiento distribuido de archivos. Este es una colección de archivos que se esparcen por un sistema distribuido. El propósito de esta parte del sistema operativo es asegurar que los usuarios pueden acceder a estos archivos, de forma que no necesiten conocer la localización de los archivos.
- El software de autentificación, el cual comprueba que un usuario que desee utilizar un sistema distribuido pueda en efecto hacerlo.
- El software intermedio orientado a mensajes que gestiona el envío de mensajes desde clientes a servidores y viceversa.

El software intermedio de servicios es el software asociado a un servicio en particular. Entre los ejemplos típicos de este tipo de software se incluyen:
- Un software que permite a bases de datos diferentes conectarse a una red cliente-servidor. Probablemente el mejor ejemplo de este tipo de software sea la ODBC (Conectividad abierta de bases de datos) Open Database Connectivity)) producida por Microsoft. Esta permite que existan felizmente en una red la vasta mayoría de sistemas de gestión de bases de datos.
- Un software específico de objetos distribuidos tal como el que está asociado a CORBA. CORBA es una tecnología de objetos distribuida que permite a objetos escritos en una gran variedad de lenguajes que coexistan felizmente en una red de tal forma que cualquier objeto pueda enviar mensajes a otro objeto. El software intermedio de CORBA tiene que ver con funciones tales como configurar objetos distribuidos, comunicación y seguridad entre objetos.
- Un software intermedio de Web asociado al protocolo HTTP.
- Un software intermedio de software de grupo que administra los archivos que describen a los equipos de trabajo y sus interacciones.
- Un software intermedio asociado a productos de seguridad específicos. Un buen ejemplo es el software intermedio asociado a lo que se conoce como conexiones (sockets) seguras. Estas son conexiones que se pueden utilizar para enviar datos seguros en una red de tal forma que hace imposible que intrusos escuchen a escondidas los datos.
Un ejemplo de software intermedio
El software intermedio orientado a mensajes es el software intermedio que administra el flujo de mensajes hacia y desde un cliente. Esta sección estudia detalladamente este software con el fin de proporcionar un ejemplo de un tipo específico de software intermedio. Para referirse al software intermedio orientado a mensajes a menudo se utiliza la sigla MOM. Es el que gestiona de forma eficaz las colas que contienen mensajes que proceden y que se envían desde servidores. La Figura 28.2 muestra un número de configuraciones. La Figura 28.2 (a) muestra un número de clientes que acceden a dos colas, una cola de entrada a la que envían los mensajes y una cola de salida desde la que toman los mensajes y un único servidor que lee y escribe los mensajes. Un mensaje de entrada típico podría ser el que ordena al servidor que encuentre algunos datos en una base de datos y un mensaje de salida podría ser los datos que se han extraído de la base de datos. La Figura 28.2 (b) muestra múltiples clientes y un número de instanciaciones del programa servidor que trabajan concurrentemente en las mismas colas.
Hay que establecer una serie de puntualizaciones a cerca de un software MOM:
- No se necesita establecer una conexión especializada mientras que el cliente y el servidor interactúan.
- El modelo de interacción entre clientes y servidores es, en efecto, muy simple: los clientes y servidores interactúan mediante colas. Todo lo que necesita hacer el programador del cliente y del servidor es enviar un mensaje a la cola. El software MOM a nivel de programador es muy simple.
- Utilizando el software MOM la comunicación es asíncrona, hasta el punto en que la mitad de la pareja cliente-servidor puede que no esté comunicándose con la otra parte. Por ejemplo, el cliente puede que no esté ejecutándose: puede detenerse para su mantenimiento y que el servidor siga mandando mensajes a colas MOM. Puede que el cliente haya cerrado con algunos mensajes a la espera de que los procese el servidor. El servidor puede colocar estos mensajes en la cola de manera que la próxima vez que el cliente se conecte pueda leer los mensajes. Este escenario es el ideal para la informática móvil.
- Arquitecturas Estructuradas
El propósito de esta sección es explorar la idea de una arquitectura estratificada para una aplicación cliente-servidor y se limita a describir las arquitecturas populares de dos y de tres capas. Una arquitectura de dos capas de una aplicación cliente-servidor consiste en una capa de lógica y presentación, y otra capa de bases de datos. La primera tiene que ver con presentar al usuario conjuntos de objetos visuales y llevar a cabo el procesamiento que requieren los datos producidos por el usuario y los devueltos por el servidor. Por ejemplo, esta capa contendría el código que monitoriza las acciones de pulsar botones, el envío de datos al servidor, y cualquier cálculo local necesario para la aplicación. Estos datos se pueden almacenar en una base de datos convencional, en un archivo simple o pueden ser incluso los datos que están en la memoria. Esta capa reside en el servidor.
Normalmente las arquitecturas de dos capas se utilizan cuando se requiere mucho procesamiento de datos. La arquitectura del servidor Web de navegador es un buen ejemplo de una arquitectura de dos capas. El navegador del cliente reside en la capa de lógica y presentación mientras que los datos del servidor Web-las páginas Web- residen en las capa de la base de datos.
Otro ejemplo de aplicación en donde se emplearía normalmente una arquitectura de dos capas es una aplicación simple de entrada de datos, donde las funciones principales que ejercitan los usuarios es introducir los datos de formas muy diversas en una base de datos remota; por ejemplo, una aplicación de entrada de datos de un sistema bancario, donde las cuentas de usuarios nuevos se teclean en una base de datos central de cuentas.
El cliente de esta aplicación residirá en la capa lógica y de presentación mientras que la base de datos de cuentas residiría en la capa de base de datos. Las dos aplicaciones descritas anteriormente muestran la característica principal que distingue a las aplicaciones de capas de otras aplicaciones que emplean más capas por el hecho de que la cantidad de procesamiento necesario es muy pequeña. Por ejemplo, en la aplicación de validación de datos, el Único procesamiento requerido del lado del cliente sería la validación de datos que se llevaría a cabo sin recurrir a la base de datos de las cuentas. Un ejemplo sería comprobar que el nombre de un cliente no contiene ningún dígito. El resto de la validación se haría en la capa de la base de datos y conllevaría comprobar la base de datos para asegurar que no se añadieron registros duplicados de clientes a la base de datos. Reece ha documentado los criterios que se deberían utilizar cuando consideramos adoptar una arquitectura cliente servidor de dos capas. Estos son los criterios:
- ¿Utiliza la aplicación una única base de datos?
- ¿Se localiza el procesador de base de datos en una sola CPU?
- ¿Es relativamente estática la base de datos en lo que se refiere a predecir un crecimiento pequeño de tamaño y estructura?
- ¿Es estática la base del usuario?
- ¿Existen requisitos fijos o no hay muchas posibilidades de cambio durante la vida del sistema?
- ¿Necesitará el sistema un mantenimiento mínimo?
Aunque algunas de estas cuestiones van enlazadas (los cambios en los requisitos dan lugar a las tareas de mantenimiento), se trata de un cantidad bien amplia de preguntas que deberían de tenerse en cuenta antes de adoptar una arquitectura de dos capas.
Cuando una aplicación implica un procesamiento considerable, entonces comienzan a surgir problemas con la arquitectura de dos capas, particularmente aquellas aplicaciones que experimentan cambios de funcionalidad a medida que se van utilizando. También, una arquitectura de dos capas, donde no hay muchas partes de código de procesamiento unidas a acciones tales como pulsación de botones o introducción de texto en un campo de texto, está altamente orientada a sucesos específicos y no a los datos subyacentes de una aplicación, y de aquí que la reutilización sea algo complicado.

La Figura 28.3 muestra una arquitectura de tres capas. Se compone de una capa de presentación, una capa de procesamiento (o capa de servidor de solicitudes) y una capa de base de datos. La capa de presentación es la responsable de la presentación visual de la aplicación, la capa de la base de datos contiene los datos de la aplicación y la capa de procesamiento es la responsable del procesamiento que tiene lugar en la aplicación. Por ejemplo, en una aplicación bancaria el código de la capa de presentación se relacionaría simplemente con la monitorización de sucesos y con el envío de datos a la capa de procesamiento. Esta capa intermedia contendría los objetos que se corresponden con las entidades de la aplicación; por ejemplo, en una aplicación bancaria los objetos típicos serían los bancos, el cliente, las cuentas y las transacciones.
La capa final sería la capa de la base de datos. Ésta estaría compuesta de los archivos que contienen los datos de la aplicación. La capa intermedia es la que conlleva capacidad de mantenimiento y de reutilización. Contendrá objetos definidos por clases reutilizables que se pueden utilizar una y otra vez en otras aplicaciones. Estos objetos se suelen llamar objetos de negocios y son los que contienen la gama normal de constructores, métodos para establecer y obtener variables, métodos que llevan a cabo cálculos y métodos, normalmente privados, en comunicación con la capa de la base de datos. La capa de presentación enviará mensajes a los objetos de esta capa intermedia, la cual o bien responderá entonces directamente o mantendrá un diálogo con la capa de la base de datos, la cual proporcionará los datos que se mandarían como respuesta a la capa de presentación.
El lugar donde va a residir la capa intermedia depende de la decisión sobre el diseño. Podría residir en el servidor, que contiene la capa de base de datos; por otro lado, podría residir en un servidor separado. La decisión sobre dónde colocar esta capa dependerá de las decisiones sobre diseño que se apliquen, dependiendo de factores tales como la cantidad de carga que tiene un servidor en particular y la distancia a la que se encuentra el servidor de los clientes. La localización de esta capa no le resta valor a las ventajas que proporciona una arquitectura de tres capas:
- En primer lugar, la arquitectura de tres capas permite aislar a la tecnología que implementa la base de datos, de forma que sea fácil cambiar esta tecnología. Por ejemplo, una aplicación podría utilizar en primer lugar la tecnología relaciona para la capa de base de datos; si una base de datos basada en objetos funciona tan eficientemente como la tecnología relacional que se pudiera entonces integrar fácilmente, todo lo que se necesitaría cambiar serían los métodos para comunicarse con la base de datos.
- Utiliza mucho código lejos del cliente. Los clientes que contienen mucho código se conocen como clientes pesados (gruesos). En un entorno en donde se suele necesitar algún cambio, estos clientes pesados pueden convertirse en una pesadilla de mantenimiento. Cada vez que se requiere un cambio la organización tiene que asegurarse de que se ha descargado el código correcto a cada cliente. Con una capa intermedia una gran parte del código de una aplicación cliente-servidor reside en un lugar (o en un número reducido pequeño de lugares si se utilizan servidores de copias de seguridad) y los cambios de mantenimiento ocurren de forma centralizada.
- La idea de las tres capas encaja con las prácticas orientadas a objetos de hoy en día: todo el procesamiento tiene lugar por medio de los mensajes que se envían a los objetos y no mediante trozos de código asociados a cada objeto en la capa de presentación que se está ejecutando.
Lo que merece la pena destacar, llegado este punto, es que existe una diferencia entre la capa intermedia del servidor de la aplicación y el software intermedio (middleware). Mientras que el primero describe el software de la aplicación que media entre el cliente y el servidor, el segundo se reserva para el software de sistemas.
- Protocolos
Con objeto de describir lo que es exactamente un protocolo, utilizaré un pequeño ejemplo: el de un cliente que proporciona servicios bancarios para casa, permitiendo, por ejemplo, que un cliente consulte una cuenta cuyos datos residen en el servidor. Supongamos que el cliente se comunica con el servidor que utiliza una serie de mensajes que distinguen las funciones requeridas por el cliente, y que también se comunica con otros datos requeridos por el servidor. Por ejemplo, el cliente puede ejercer la función de consultar un saldo de cuenta tecleando un número de cuenta en un cuadro de texto y pulsando el botón del ratón el cual enviará el mensaje al servidor. Este mensaje podría ser de la forma
CS*<Número de cuenta,
Donde CS (Consulta del Saldo) especifica que el usuario ha consultado una cuenta para obtener el saldo con el número de cuenta que identifica la cuenta. El servidor entonces recibirá este mensaje y devolverá el saldo; el mensaje que el servidor envía podría tener el formato
S*<cantidad de saldo>,
El cliente interpretara este mensaje y visualizara el saldo en algún elemento de salida. Si el cliente quisiera consultar los números de cuentas de todas las cuentas con las que él o ella están asociados, el mensaje entonces podría ser de la forma
CC *
Donde CC (Consulta de Cuenta) solicita las cuentas, y en cuya función ya no se requieren más datos. El servidor podría responder con un mensaje que comenzara con (Información de Cuenta) y que estuviera formado por números terminados con asteriscos. Por ejemplo,
IC"223899 7*88765 "882234
Los mensajes que he descrito forman un protocolo sencillo que comunica funcionalidad y datos entre dos entidades (un cliente y un servidor) en la red.
Un punto importante acerca de los protocolos es que siempre que se utiliza un mecanismo para la comunicación en una red existe un protocolo. Por ejemplo, los objetos distribuidos son objetos que se encuentran en localizaciones remotas en una red, y es mediante la utilización de un protocolo la manera en que se envían los mensajes, aunque la programación de estos objetos esté a un nivel superior por debajo de la programación y oculta al programador.
El protocolo que he descrito se asemeja a un juguete y también a un protocolo de aplicaciones. Merece la pena entrar en el estudio de algunos protocolos más reales que estén asociados a los servicios de nivel de sistema.
IP e ICMP
IP, el protocolo que ejecuta Internet es un protocolo muy complicado, y una descripción completa estaría fuera del ámbito de este libro, ya que la descripción de este protocolo necesitaría un libro entero que le hiciera justicia. Debido a esto me centraré en una parte pequeña del protocolo, aunque importante, conocida como ICMP (Internet Control Message Protocol). Protocolo de mensajes de control de Internet que se utiliza para monitorizar los errores y problemas de la red que utiliza IP. En la Figura 28.4 se muestra el formato de los mensajes que forman parte del protocolo.
El campo Tipo especifica el tipo de error que ha ocurrido. Por ejemplo, este campo indicaría que el destino de un mensaje era inalcanzable. El campo Código contiene la información secundaria que se utiliza para proporcionar una interpretación más detallada del campo Tipo. El campo de Suma de verificación es utilizado por el software para comprobar que la transmisión del mensaje ICMP se ha llevado a cabo correctamente. Los dos campos restantes contienen los datos que permitirán al software de comprobación localizar el problema originado.
ICPM es utilizado por IP para llevar a cabo el procesamiento básico de errores y también para incrementar la eficacia de la red. Por ejemplo, se podría utilizar para llevar a cabo el cambio de dirección del mensaje si una computadora, que se encontrara en el camino inicial del mensaje, descubriera una ruta mejor.
POP3
POP3 (Post Office Protocol version 3) (Protocolo de Oficina de Correos versión 3) se utiliza para el envío y la recepción de correo electrónico. Es un protocolo sencillo y es ampliamente utilizado. En esta sección realizaré un estudio de algunas de sus características.
Existen varios protocolos de correo, entre los que se incluyen SMTP, IMAP y diferentes versiones de POP. Probablemente el más complicado de estos sea IMAP, el cual incluye funciones secundarias y un conjunto de mensajes más rico que POP. El propósito de POP es posibilitar a los usuarios acceder al correo remoto y consta de una serie de comandos que permiten a los programas de usuario interactuar con un servidor de correo POP. El estándar
POP3 describe un grupo de mensajes posibles que pueden enviarse al servidor de correo POP3 y el formato de los mensajes es devuelto por el servidor. La Tabla 28.1 muestra un subconjunto pequeño del protocolo POP3.

El protocolo HTTP
Este es uno de los protocolos más importantes que se utilizan dentro de Internet; es el protocolo que rige la comunicación entre un cliente que utiliza un navegador Web tal como Internet Explorer y un servidor
Web. La función principal de un servidor Web es poner a disposición de clientes páginas Web. Estos clientes utilizarán un navegador que les conectará al puerto 80 en el servidor Web; este es el puerto estándar que se utiliza para tales servidores. El navegador que está utilizando el cliente .enviará mensajes definidos por el protocolo HTTP y serán interpretados por el servidor que llevará a cabo operaciones tales como devolver una página Web o procesar algún formulario que esté insertado dentro de una página. A continuación, se muestra un ejemplo que ilustra lo descrito anteriormente
GET/index.html HTTP/ 1.1
Este es el mensaje que envía un navegador cuando quiere visualizar una página en particular. Este mensaje se puede haber generado de diferentes maneras. Por ejemplo, el usuario puede haber pinchado con el ratón en un determinado enlace en un documento Web que señala a la página solicitada. La línea anterior contiene la palabra reservada GET, la cual especificaba que se iba a devolver un archivo, y especificaba también el nombre del archivo que sigue al carácter '/' (index.htm1) y la versión del protocolo que utiliza el navegador que va a enviar el mensaje. El servidor también utilizará el protocolo HITP para enviar mensajes de vuelta al cliente. Por ejemplo, el mensaje
HTTP/1.1 200 OK
Significa que el servidor, que está utilizando HTTP versión 1.1, ha procesado con éxito la petición iniciada por el cliente. El código 200 en este caso es un ejemplo del código de estado que indica éxito.
- Un sistema de comercio electrónico
¿Qué es el comercio electrónico?
Para ilustrar la apariencia de un sistema distribuido examinaremos un ejemplo tomado de un área de aplicación conocida como comercio electrónico. En un sentido amplio, el término «comercio electrónico» (Ecommerce) se puede definir como la aplicación de la tecnología de sistemas distribuidos que apoya las operaciones comerciales. A continuación, se detallan algunos de dichos sistemas:
- Sistemas para vender algunos artículos o servicios utilizando Internet, donde los clientes interactúan con el sistema que utiliza navegadores. Entre los sistemas típicos de comercio electrónico de esta categoría se incluyen los que venden libros, ropa y CDs.
- Sistemas para simular alguna actividad comercial en tiempo real utilizando tecnología de red. Un buen ejemplo de este tipo de sistemas es una subasta en la red. Un sistema de subasta típico solicitaría artículos a los usuarios de Internet, ubicaría los datos en una página Web y entonces comenzaría la oferta para ese artículo. Normalmente la compañía de subastas especificaría un período de oferta para así darla por finalizada.
- Sistemas que proporcionan algún servicio basado en red para usuarios. Probablemente los más conocidos son los que ofrecen cuentas de correo gratis, donde los ingresos de dicha empresa probablemente procedan de la publicidad en las páginas Web que se utilizan para ese sitio Web. Estas son compañías que mediante un honorario monitorizan su sitio Web y le envían un mensaje, normalmente por correo electrónico o mediante un buscador si han detectado un problema, como el mal funcionamiento del servidor que se utiliza para el sitio Web.
- Sistemas que proporcionan servicios de asesoramiento. Los sistemas típicos de este tipo son los que procesan una descripción de artículos, como un CD, para los que establecerán el mejor precio, después de haber explorado un número de sistemas de venta en la red.
- Sistemas internos que el cliente no ve, pero que dan soporte a más actividades comerciales convencionales. Por ejemplo, un sistema que apoya el suministro de mercancías a un comerciante minorista de la calle.
- Sistemas de publicidad. Muchos de los ingresos del comercio electrónico proceden de la publicidad en línea. Muchas páginas Web asociadas a las aplicaciones de comercio electrónico contendrán pequeños espacios publicitarios conocidos como banners. Estos anuncios se pueden «pinchar», conduciendo así al usuario del navegador a un sitio Web el cual normalmente vende algún producto o servicio. Los sistemas de publicidad son una forma particular de sistemas de comercio electrónico que llevan a cabo funciones tales como vender un banner (espacio publicitario), monitorizando el éxito de estos anuncios y la administración del pago de los honorarios de publicidad.
Estas forman un conjunto típico de aplicaciones que están bajo el «banner» del comercio electrónico. En la parte restante de esta sección observaremos una aplicación típica de comercio electrónico que administra la venta de un artículo. Esto es lo que piensa cualquier persona de una aplicación de comercio electrónico, aunque espero que después de leer este preámbulo este sistema se considerará sólo como un tipo de sistema.
Un sistema típico de correo electrónico
Con objeto de entender la naturaleza de los sistemas Cliente-servidor, merece la pena examinar un ejemplo de una de las áreas del comercio electrónico. Es un sistema para administrar las ventas de una gran librería que tenga una funcionalidad similar a la que exhiben grandes librerías como Blackwells o la filial británica de Amazon. Las funciones típicas que un sistema como éste proporciona son las siguientes:
La provisión de servicios de Catálogo. Cada libro que venda una compañía estará en catálogo y la página Web proporcionará la descripción de ese libro. La información típica que se proporciona sobre un libro es el nombre, autor, editorial y precio.
La provisión de servicios de búsqueda. El usuario de dicho sistema necesitará navegar por el catálogo para decidir si va a comprar un libro. Esta navegación se podría realizar de muchas maneras diferentes: desde navegar secuencialmente desde el primer libro que aparece, hasta navegar utilizando consultas de búsqueda tal como el título de un libro o su ISBN.
La provisión de servicios de pedidos. Cuando un cliente de un sitio de comercio electrónico quiere comprar un libro, el sistema le proporcionará algún servicio para poderlo hacer y, normalmente, mediante tarjetas de crédito. Generalmente cuando el cliente realiza el pedido de un libro, a continuación se le solicitan los datos de la tarjeta de crédito. Algunos sistemas de pedidos suelen quedarse con los datos de las tarjetas de forma permanente de manera que no se requiere que el cliente proporcione los datos cada vez que haga un pedido.
La provisión de servicios de seguimiento. Estos servicios posibilitarán al cliente seguir con el proceso de una compra utilizando su navegador. Las páginas Web personalizadas para el cliente describirán el desarrollo de un pedido: si ya se ha enviado, si está esperando porque el libro no está en stock, y cuál es la fecha en la que se espera enviar el pedido.
El procesamiento de revisiones. Un servicio ofrecido por los sitios de ventas de libros más sofisticados y es el que proporciona el medio por el que los clientes pueden escribir revisiones de los libros a comprar. Estas revisiones se pueden comunicar al vendedor o bien por correo electrónico o por una página Web especializada.
La provisión de un servicio de conferencia. Un servicio de conferencia capacita a un grupo de clientes para interactuar entre ellos enviando mensajes a una conferencia, entendiendo por conferencia algo dedicado a un tema específico tal como, por ejemplo, la última novela de Robert Goddard o el estado de la ficción criminal. Tales servicios no proporcionan ingresos directamente a un vendedor de libros en red. Sin embargo, sí pueden proporcionar información Útil sobre las tendencias en las compras de libros de las que el personal de ventas de una librería pueden sacar provecho.
La provisión de noticias o boletines para clientes. Un servicio popular que se encuentra en muchos sitios de comercio electrónico dedicados a la venta de un producto es el de proporcionar información por medio del correo electrónico. Para el sitio de ventas de libros que se está describiendo en esta sección se incluirían mensajes tal como textos de revisiones, ofertas especiales o mensajes relacionados con un pedido específico, tal como el hecho de haberse despachado.
Control y administración del stock. Este es un conjunto de funciones que están ocultas para el usuario del sistema de ventas de libros pero que son vitales para el sistema. Estas funciones se asocian a las actividades mundanas, tales como hacer pedidos de libros, hacer el seguimiento de los stocks y reordenar y proporcionar información de ventas al personal responsable de los pedidos.
Informes financieros. Estos son de nuevo un conjunto de funciones que están ocultas ante los ojos del usuario del sistema de ventas de libros pero que son vitales. Proporcionan la información para la gestión financiera de la compañía que ejecuta el sistema y proporciona la información de datos tales como las ventas día a día, anuales y datos más complejos tales como la efectividad de ciertas estrategias de ventas respecto a las ventas de los libros que eran el tema de estas estrategias.
Se puede decir que estas son un conjunto típico de funciones mostradas por el comercio electrónico dedicado a vender productos; en nuestro caso el producto son libros, aunque no hay ninguna razón para no haber elegido, por ejemplo, ropa, CDs, antigüedades, etc., aunque las funciones del sistema variarían un poco; por ejemplo, en un sitio especializado en vender ropa no habría razón por la que implementar las funciones que están conectadas con las revisiones de productos.
Antes de estudiar la arquitectura de dicho sistema merece la pena hacer hincapié en el desarrollo de tales sistemas. Durante el nivel de análisis hay poca diferencia entre el sistema de comercio electrónico y un sistema más convencional, tal como el que depende de los operadores telefónicos para anotar los pedidos y donde el catálogo se imprime y se envía a los clientes de la forma convencional. Ciertamente existirán funciones que no estarán dentro de tales sistemas convencionales, como por ejemplo los que tienen que ver con las revisiones; sin embargo, la mayor parte de las funciones son muy similares, y es posible que se lleven a cabo de forma diferente; por ejemplo, el proceso de obtener los datos de las tarjetas de crédito sería llevado a cabo por un operador y no por una página Web.
En la Figura 28.5 se muestra la arquitectura técnica de un sistema de libros típico. Los componentes de este sistema son:
Clientes Web. Estos ejecutarán un navegador que interactúa con el sistema y que principalmente lleva a cabo funciones de navegar sobre catálogos y hacer pedidos.
Un servidor Web. Este servidor contendrá todas las páginas Web a las que el cliente irá accediendo y se comunicará con el resto del sistema para proporcionar información tal como la disponibilidad de un libro. Normalmente existirá más de un servidor Web disponible para enfrentarse con un fallo del hardware. Si el servidor Web estaba funcionando y se viene abajo, dicho suceso sería extremadamente seno y se correspondería con las puertas de una librería convencional cerrada a los clientes impidiendo su entrada. Debido a las cajas registradoras, los sistemas de correo electrónico que tienden a ser muy críticos para un negocio tendrán hardware reproducido, incluyendo reproducciones de servidores de Web.

Un servidor de correo. Este servidor mantendrá listas de correos de clientes que, por ejemplo, han indicado que desean estar puntualmente informados de las ofertas especiales y los libros nuevos que se están publicando. Este servidor se comunicará con el servidor Web principal, ya que los clientes proporcionarán sus direcciones de correo y los servicios que quieren, interactuando con las páginas Web que visitan. Esto ilustra un tema importante acerca de los clientes y los servidores: no hay una designación fuerte o rápida de lo que es un cliente o un servidor de un sistema de comercio electrónico: esto depende realmente de la relación entre las entidades implicadas. Por ejemplo, el servidor Web actúa como un servidor para los clientes que ejecutan un navegador, pero actúa como un cliente con el servidor de correo al cual le proporciona direcciones de correo para sus listas de correo.
Un servidor de conferencia. Este es un servidor que administra conferencias. Lee en las contribuciones a la conferencia, visualiza estas contribuciones en una ventana asociada a una conferencia y borra cualquier entidad que no esté actualizada.
Servidores de bases de datos. Son servidores que administran las bases de datos asociadas a la aplicación de comercio. Aquí se incluye la base de datos principal de libros, la cual contiene datos de cada libro; la base de datos de pedidos que contiene datos de los pedidos que han realizado los clientes, todos los que no se han cumplido tanto anteriores como actuales; la base de datos de clientes que contiene datos de los clientes de los vendedores de libros; y una base de datos que contiene datos de las ventas de libros concretos; esta base de datos es particularmente útil para muchos vendedores de libros en la red, puesto que les permite publicar las listas de los libros más vendidos junto con las ofertas especiales de esos libros. En muchos sistemas de comercio electrónico estas bases de datos son implementadas en varios servidores de bases de datos especializados que son duplicados: tales bases de datos son vitales para el funcionamiento de una compañía de comercio electrónico: si el servidor de bases de datos funcionaba mal y no existen servidores duplicados, ocurría algo muy serio, ya que no tendrían ingresos y los vendedores en red obtendrían una reputación muy pobre. Un punto importante a tener en cuenta sobre esta parte del sistema es que no hay razón para que una tecnología anterior, tal como un mainframe que ejecuta una monitorización de transacciones se pueda utilizar para funciones de bases de datos; en realidad muchos de los sistemas de comercio electrónico se componen de un servidor Web frontal que se comunica con un sistema servidor no cliente. Este sistema servidor no cliente es el que lleva existiendo ya desde hace algún tiempo y se utilizaba para un procesamiento más convencional como es el de tomar pedidos por teléfono. Los servidores de bases de datos se mantendrán actualizados por medio de un software de sistemas que detecta cuando se va a aplicar una transacción a una base de datos: primero aplica la transacción a la base de datos que se está utilizando en ese momento y, a continuación, la aplica a todas las bases de datos duplicadas.
Un servidor de monitorización. Este es el servidor que se utiliza para monitorizar la ejecución del sistema. Es utilizado por un administrador del sistema para comprobar el funcionamiento correcto del sistema y también para ajustar el sistema de manera que se archive un rendimiento óptimo.
- Tecnologías usadas para el comercio electrónico
Existen varias tecnologías basadas en red que se utilizan para las aplicaciones de comercio electrónico. Antes de describirlas merece la pena decir que muchas tecnologías antiguas todavía se utilizan para este tipo de aplicación; el mejor ejemplo es el uso de la tecnología de bases de datos relacionales para proporcionar almacenes de datos a gran escala.
Conexiones (sockets)
Un socket es un tipo de conducto que se utiliza para conectarse a una computadora conectada a una red y basada en TCP/IP. El socket se configura de tal manera que los datos pueden ser bajados desde el cliente y devueltos al mismo. Los lenguajes de programación modernos, como Java, proporcionan servicios de alta calidad por medio de los cuales un socket se puede conectar mediante «programación» a una computadora cuya dirección de Internet sea conocida y donde los datos se puedan enviar por este conducto. La programación necesaria para esto normalmente no es más complicada que la programación que se requiere para escribir y leer datos de un archivo. Los sockets son una implementación a bajo nivel de la conectividad; dentro de las utilizaciones típicas de un socket están las aplicaciones de conferencia, donde una entrada a una conferencia se enviaría al servidor de conferencia que utiliza una configuración de sockets en el servidor. Los sockets son un mecanismo de bajo nivel, pero una forma muy eficiente de comunicar datos en un sistema distribuido que ejecuta el protocolo TCP/IP.
Objetos distribuidos
Un objeto distribuido es aquel que reside en una computadora, normalmente un servidor, en un sistema distribuido. Otras computadoras del sistema pueden enviar mensajes a este objeto como si residiera en su propia computadora. El software del sistema se hará cargo de varias funciones: localizar el objeto, recoger los datos que se requieren para el mensaje y enviarlos a través del medio de comunicación que se utiliza para el sistema. Los objetos distribuidos representan un nivel más alto de abstracción que las conexiones (sockets): a parte de algún código de inicialización, el programador no es consciente del hecho de que el objeto reside en otra computadora. Actualmente existen tres tecnologías de objetos distribuidos en pugna:
RMI. Esta es la tecnología asociada al lenguaje de programación de Java. Es un enfoque Java puro en el que solo los programas escritos en ese lenguaje se pueden comunicar con un objeto RMI distribuido. Es la tecnología ideal para sistemas cerrados de Java; estos sistemas generalmente tendrán pocas conexiones o ninguna con otros sistemas
.
DCOM. Esta es una tecnología desarrollada por la compañía Microsoft y permite que programas escritos en lenguajes tales como Visual Basic y Visual J++ (la variedad de Java desarrollada por Microsoft) se comuniquen con los objetos que están en computadoras remotas.
CORBA. Esta es la tecnología de objetos distribuidos más sofisticada. Fue desarrollada por un consorcio de compañías informáticas, clientes y compañías de software. La característica más importante del enfoque CORBA es que es multilenguaje, donde los programadores pueden utilizar diferentes lenguajes de programación para enviar mensajes a objetos CORBA: las interfaces CORBA existen para lenguajes tales como Java, FORTRAN, LISP, Ada y Smalltalk. CORBA está al principio de su desarrollo, sin embargo, amenaza con convertirse en la tecnología dominante para objetos distribuidos.
La principal ventaja de los objetos distribuidos sobre la de los sockets es el hecho de que como abarca enteramente el paradigma de orientación a objetos se puede emplear los mismos métodos de análisis y diseño que se utilizan para la tecnología de objetos convencional.
Espacios
Esta es una tecnología que se encuentra en un nivel de abstracción incluso más alto que los objetos distribuidos. Fue desarrollada por David Gelemter, un profesor de la Universidad de Yale. La tecnología de espacios concibe un sistema distribuido en base a un gran almacén de datos persistentes donde las computadoras de un sistema distribuido pueden leer o escribir. No concibe el sistema distribuido como una serie de programas que pasan mensajes a los demás utilizando un mecanismo como los sockets, o como una serie de objetos distribuidos que se comunican utilizando métodos. Por el contrario, la tecnología de espacios conlleva procesos como escribir, leer o copiar datos a partir de un almacén persistente. Un programador que utiliza esta tecnología no se preocupa por detalles como dónde están almacenados los datos, qué proceso va a recoger los datos y cuándo los va a recoger. Esta tecnología se encuentra sólo al principio, aunque las implementaciones llevan ya disponibles durante algún tiempo para lenguajes como C y C++; sin embargo, la implementación de la tecnología dentro de Java como Javaspaces debería asegurar que cada vez se utilizará más para las aplicaciones principales.
CGI
El término CGI (Common Gateway Interface) significa Interfaz común de pasarela. Es la interfaz con el servidor Web al cual se puede acceder mediante los programas que se ejecutan en el servidor. Gran parte de la interactividad asociada a las páginas Web se implementa programando el acceso a la CGI. Por ejemplo, cuando el usuario de un navegador accede a una página que contiene un formulario, éste lo rellena y lo envía al servidor Web, programa que accede al CGI, procesa el formulario, y lleva a cabo la funcionalidad asociada al formulario; por ejemplo, recuperando los datos solicitados en el formulario. La programación CGI se puede llevar a cabo en varios lenguajes de programación, aunque el lenguaje seleccionado ha sido Perl, lenguaje de procesamiento de cadenas, existen otros entre los que se incluyen, por ejemplo, Java y C++, que contienen los servicios para el procesamiento CGI. Recientemente los que desarrollan Java han proporcionado a los programadores el servicio de utilizar Java para este tipo de programación que utiliza la tecnología conocida como sewlets. Estos trozos pequeños de código Java son insertados en un servidor de Web y se ejecutan cuando ocurre un suceso, como enviar un formulario. Los servlets ofrecen un alto grado de portabilidad sobre otros lenguajes de programación.
Contenido ejecutable
Este es el término que se aplica a la inclusión en una página Web de un programa que se ejecuta cuando la página es recuperada por un navegador. Este programa puede llevar a cabo un número diverso de funciones entre las que se incluyen la animación y la presentación de un formulario al usuario para insertar datos. Existen varias tecnologías que proporcionan servicios para insertar contenido ejecutable en una página Web. Aquí se incluyen applets, Active X y Javascript. Un applet es un programa escrito en Java que interactúa con una página Web. Lo importante a señalar de esta tecnología es que es portátil: el código Java se puede mover fácilmente desde un sistema operativo a otro, pero es potencialmente inseguro. La razón de por qué los applets son inseguros es que se pueden utilizar como medio de transmisión de virus y otros mecanismos de acceso a una computadora. Cuando una página de navegador que contiene un applet es descargada por un navegador, es lo mismo que cargar un programa en la computadora cliente que ejecuta el navegador. Afortunadamente los diseñadores de Java desarrollaron el lenguaje de tal manera que es inmensamente difícil escribir applets que provoquen violaciones en la seguridad. Desafortunadamente la solución que se adoptó evita acceder a los recursos de una computadora cliente o ejecutar otro programa en la computadora. Aunque se han hecho muchas mejoras en los applets que permiten un acceso limitado, el modelo principal del uso de applets está restringido a este modo de ejecución.
Active X es otra tecnología de contenido ejecutable que fue desarrollada por Microsoft. De nuevo se trata de un código de programa insertado en una página Web; la diferencia principal entre esta tecnología y los applets es el hecho de que estos trozos de código se pueden escribir en diferentes lenguajes como Visual Basic y C++. Esta forma de contenido ejecutable también sufre de posibles problemas de seguridad.
Javascript es un lenguaje de programación interpretado y sencillo que se inserta directamente en una página Web. Se diferencia de las soluciones de Active X y applets en que el código fuente de cualquier programa de guiones de Java se integra en una página Web en vez de en el código de objetos como ocurre con los applets y Active X. Javascript es un lenguaje sencillo que se utiliza para una programación relativamente a bajo nivel.
Paquetes cliente/servidor
Este término describe las colecciones de software que normalmente llevan a cabo algún tipo de procesamiento de sistemas. A continuación, se muestra un grupo de ejemplos típicos de paquetes de software:
Paquetes de reproducción de datos. Este tipo de software realiza una transacción en la base de datos y la aplica a un número de bases de datos reproducidas, evitando así acceder a estas bases de datos hasta que estén todas en sincronización.
Paquetes de seguridad. Estos son paquetes que monitorizan el tráfico dentro de un sistema distribuido y avisan al administrador de sistemas de la aparición de cualquier violación posible en la seguridad. Por ejemplo, el hecho de que alguien intente entrar en un sistema con una contraseña sin reconocer.
Monitores de transacciones. Estos son paquetes de software que administran las transacciones que tienen lugar dentro de un sistema distribuido y aseguran que se devuelvan los datos correctos como resultado de una transacción y en el orden correcto. Muchas de las funciones de estos monitores tienen que ver con asegurar que los resultados correctos se devuelvan incluso en el entorno en donde podrían aparecer errores de hardware o de transmisión.
- El diseño de sistemas distribuidos
Antes de observar algunos de los principios del diseño que se utilizan en el desarrollo de sistemas distribuidos, particularmente de sistemas de comercio electrónico, merece la pena reiterar lo que se ha señalado anteriormente: a nivel de análisis hay poca diferencia entre un sistema distribuido y un sistema local, y se basa en que el modelo de análisis de un sistema no contendrá ningún dato de diseño como el hecho de que tres computadoras, y no una solo, están llevando a cabo algún procesamiento. Esto significa que el desarrollador de un sistema distribuido se enfrentará normalmente con un modelo de objetos o un modelo funcional similar al que se mostró en las primeras partes de este libro; esta descripción irá acompañada de algunos de los tipos de computadoras y de hardware de redes que se van a utilizar. El proceso de diseño implica transformar el modelo de análisis en algún modelo físico que se implementa en los elementos de hardware del sistema.
Es necesario que el diseñador de sistemas distribuidos conozca una serie de principios de diseño. El resto de esta sección muestra un esquema de los mismos.
Correspondencia del volumen de transmisión con los medios de transmisión
Este es uno de los principios más obvios. Esto significa que para un tráfico denso de datos en un sistema distribuido se deberían utilizar medios de transmisión rápidos (y caros). El proceso de asignar tales medios normalmente tiene lugar después de haber tomado decisiones sobre la potencia de procesamiento de distribución en un sistema y, algunas veces, conlleva unas ligeras iteraciones al final de la fase de diseño.
Mantenimiento de los datos más usados en un almacenamiento rápido
Este principio también es obvio. Requiere que el diseñador examine los patrones de datos en un sistema y asegure que los datos a los que se accede frecuentemente se guarden en algún medio de almacenamiento rápido. En muchos sistemas tales datos pueden constituir no más del 5 por 100 de los datos originales almacenados en el sistema, y de esta manera permite utilizar con frecuencia las estrategias que conllevan el almacenamiento de estos datos dentro de la memoria principal.
Mantenimiento de los datos de donde se utilizan
Este principio de diseño intenta reducir el tiempo que pasan los datos en medios lentos de transmisión. Muchos de estos sistemas son en donde los usuarios acceden con frecuencia a un subconjunto de datos. Por ejemplo, un sistema distribuido usado en una aplicación bancaria contendría bases de datos con datos de las cuentas de los clientes, en donde la mayor parte de las consultas a las bases de datos de las sucursales las realizarán los clientes de esa sucursal; entonces, si los datos de un sistema bancario se distribuyen a los servidores de las sucursales, y los datos asociados a los clientes de esa sucursal están en esa sucursal, el resto de los datos podrían estar en otros servidores con otras ubicaciones, y cualquier consulta que se originara sobre los datos se tendría que comunicar a través de líneas lentas de transmisión.
Utilización de la duplicación de datos todo lo posible
La duplicación consiste en mantener múltiples copias de datos en un sistema al mismo tiempo. Existen muchas razones para la duplicación de datos. La primera es que hay que asegurar la redundancia que permite que un sistema distribuido continúe funcionando aun cuando una computadora con datos importantes quede fuera de servicio normalmente por un mal funcionamiento del hardware. La otra razón es que proporciona una forma de implementar el principio dilucidado en la sección anterior: el de asegurar que los datos estén ubicados cerca de donde se utilizan. Por ejemplo, una compañía hotelera con una base central de reservas que hace el seguimiento de todas las reservas de las habitaciones para todos sus hoteles. Es posible que esta compañía tenga dos puntos de contacto para clientes que deseen hacer las reservas: los hoteles en sí y una oficina central de reservas. Una forma de asegurar el alto rendimiento es duplicando los datos asociados a un hotel en particular y guardar los datos? en el servidor ubicado en el hotel. Esto significa que cualquier reserva realizada por el hotel solo necesitará acceder a una base de datos local y no requerirá ningún tráfico en la línea lenta de transmisión.
Esto suena a un principio muy simple de implementación sencilla. Desafortunadamente, las cosas nunca son tan simples. En el ejemplo de las reservas de hoteles no hay necesidad de que las bases de datos asociadas a los hoteles se comuniquen con la base de datos central. La razón que apoya esto es el hecho de que también habrá clientes que utilicen la oficina central de reservas, así como clientes realizando reservas de habitaciones que ofrecen los mismos hoteles. A menos que haya coordinación entre la base de datos de la oficina central de reservas y las bases de datos individuales duplicadas de cada hotel, surgirán problemas: por ejemplo, el hecho de decir que hay una habitación libre en un momento concreto en un hotel a un cliente que utiliza el servicio central de reservas aun cuando esa habitación ya ha sido reservada por otro cliente que ha llamado directamente al hotel.
El problema anterior implica que en un sistema donde hay una relación dinámica entre las bases de datos individuales existe la necesidad entonces de que cada base de datos mantenga informadas de los cambios a otras bases de datos, y de que aseguren que los cambios se reflejen en todos los datos duplicados. Esto también implica la aparición de retrasos porque las transacciones permanecerán en cola esperando a que la base de datos se sincronice con otras bases de datos. Esto no significa que se tenga que utilizar la duplicación de datos, lo que significa es que se necesita un diseño cuidadoso para minimizar la cantidad de gastos asociados a él en las transmisiones.
Hay que señalar que en los sistemas distribuidos donde existe menos relación dinámica entre los datos, se pueden emplear estrategias más simples que eliminen muchos de los gastos. Por ejemplo, un banco normalmente lleva a cabo transacciones una vez al día en las bases de datos de los clientes y normalmente después del cierre del negocio. Esto significa que un sistema bancario distribuido puede duplicar datos en sus sucursales y solamente puede volver a copiar los datos cambiados en las bases de datos una vez al día: no habría necesidad de coordinar las bases de datos con frecuencia durante el día de trabajo. Habría que señalar también que esta subsección ha tratado la duplicación de datos en función de mantener los datos cerca de los usuarios para reducir el tiempo de transmisión con medios lentos. Hay otras razones para duplicar los datos, por ejemplo una base de datos que se utiliza mucho tendrá colas de transacciones preparadas y esperando a ejecutarse. Estas colas se pueden reducir disfrutando de bases de datos idénticas mantenidas en otros servidores de bases de datos concurrentes.
Eliminar cuellos de botella
En un sistema distribuido un servidor se convierte con frecuencia en un cuello de botella: tiene que manipular tanto tráfico que se construyen grandes colas de transacciones esperando a ejecutarse, con el resultado de que los servidores que están esperando los resultados del procesamiento estarán, en el mejor de los casos, ligeramente cargados y, en el peor, inactivos. La estrategia normal para manipular cuellos de botella es compartir la carga de procesamiento entre los servidores, normalmente servidores físicamente cerca del que está sobrecargado.
Minimizar la necesidad de un gran conocimiento del sistema
Los sistemas distribuidos suelen necesitar conocer el estado del sistema completo, por ejemplo, podría ser que necesitaran conocer la cantidad de registros de una base de datos central. El hecho de necesitar este conocimiento genera más tráfico reduciendo así la eficiencia de un sistema, ya que generará tráfico extra a lo largo de las líneas de transmisión. El diseñador de un sistema distribuido en primer lugar necesita minimizar que el sistema dependa de datos globales, y entonces asegurar que el conocimiento necesario se comunique rápidamente a aquellos componentes del sistema que lo requieran.
Agrupar datos afines en la misma ubicación
Los datos que están relacionados deberían de estar dentro del mismo servidor. Por ejemplo, en una aplicación de reservas en un sistema de vacaciones, los paquetes individuales de vacaciones deberían de estar cerca de los datos que describen las reservas actuales de ese paquete. Ubicar por separado los datos en diferentes servidores asegura que los medios de baja transmisión y muy cargados se cargarán incluso más. El diseñador de un sistema distribuido debe asegurarse de que los datos relacionados gracias al hecho de que se suelen recuperar juntos tendrán que residir lo más cerca posible, preferiblemente en el mismo servidor, o si no, y no de manera tan preferible, en servidores conectados a través de medios de transmisión rápidos tales como los medios utilizados en una red de área local.
Considerar la utilización de servidores dedicados a funciones frecuentes
Algunas veces se puede lograr un mayor rendimiento mediante la utilización de un servidor de empleo específico para una función en particular en lugar de, por ejemplo, un servidor de bases de datos.
Correspondencia de la tecnología con las exigencias de rendimiento
Muchas de las tecnologías que se estudian en este capítulo tienen pros y contras, y un factor importante aquí son las demandas de rendimiento de una tecnología en particular.
Por ejemplo, como medio de comunicación, las conexiones (sockets) normalmente son un medio de comunicación mucho más rápido que los objetos distribuidos. Cuando el diseñador elige una tecnología debe de tener conocimiento de la transmisión y de las cargas de procesamiento que conlleva, y seleccionar una tecnología que minimice estas cargas.
Empleo del paralelismo todo lo posible
Una de las ventajas principales de la tecnología cliente-servidor es el hecho de que se pueden añadir servidores y, hasta cierto punto, elevar el rendimiento del sistema. Muchas funciones del comercio electrónico pueden beneficiarse de la ejecución que están llevando a cabo diferentes servidores en paralelo. Esta no es una decisión sencilla. Mediante el empleo de varios servidores, el diseñador está creando la necesidad de que estos servidores se comuniquen, por ejemplo, un servidor puede que necesite a otro para completar una tarea en particular antes de finalizar la suya propia. Esta comunicación puede introducir retrasos y, si el diseñador no tiene cuidado, pueden negar los avances de rendimiento que se han logrado utilizando el paralelismo.
Utilización de la compresión de datos todo lo posible
Se dispone de un grupo de algoritmos que compriman datos y que reduzcan el tiempo que tardan los datos en transferirse entre un componente de un sistema distribuido y otro componente. El único gasto que se requiere para utilizar esta técnica es tiempo del procesador y la memoria necesaria para llevar a cabo la compresión en la computadora del emisor y la descompresión en la computadora del receptor.
Diseño para el fallo
Un fallo de hardware en la mayoría de los sistemas de comercio electrónico es una catástrofe: para los sistemas de ventas en red esto es equivalente a echar el cierre a los clientes. Una parte importante del proceso de diseño es analizar los fallos que podrían aparecer en un sistema distribuido y diseñar el sistema con suficiente redundancia como para que dicho fallo no afecte seriamente y, en el mejor de los casos, que se pueda reducir el tiempo de respuesta de ciertas transacciones. Una decisión normal que suele tomar el diseñador es duplicar los servidores vitales para el funcionamiento de un sistema distribuido. Una estrategia en los sistemas de alta integridad es que un servidor se reproduzca tres veces y que cada servidor lleve a cabo la misma tarea en paralelo. Cada servidor produce un resultado a comparar. Si los tres servidores aceptan el resultado, éste pasa a cualquier usuario o servidor que lo requiera; si uno de los servidores no está de acuerdo, entonces surge un problema y el resultado de la mayoría se pasa informando al administrador de sistemas del posible problema. La duplicación de servidores como estrategia de mitigación de fallos puede utilizarse junto con el diseño de un sistema para lograr el paralelismo en las tareas.
Minimizar la latencia
Cuando los datos fluyen de una computadora a otra en un sistema distribuido a menudo tiene que atravesar otras computadoras. Algunas de estas computadoras puede que ya tengan unos datos que expidan funcionalidad; es posible que otras procesen los datos de alguna manera. El tiempo que tardan las computadoras es lo que se conoce como latencia. Un buen diseño de sistema distribuido es el que minimiza el número de computadoras intermediarias.
Epílogo
Este ha sido un estudio breve aunque necesario, y se han tratado las diferentes estrategias de diseño que se utilizan en los sistemas distribuidos que implementan las funciones del comercio electrónico. Un punto importante a tener en cuenta antes de abandonar esta sección es que una estrategia puede militar contra otra, minimizar la latencia y duplicar bases de datos pueden ser dos estrategias opuestas: incrementar el número de bases de datos duplicadas incrementa la latencia de un sistema; como consecuencia, el diseño de sistemas distribuidos, más que otra cosa, es un arte.
- Ingeniería de seguridad
El incremento masivo en la utilización pública de sistemas distribuidos ha dado lugar a algunos problemas graves con la seguridad. Los sistemas distribuidos anteriores se suelen localizar en un lugar físico utilizando tecnologías tales como redes de área local. Dichos sistemas estaban físicamente aislados de los usuarios externos y como consecuencia la seguridad, aunque es un problema, no era un problema enorme como lo es ahora para los sistemas de comercio electrónico a los que pueden acceder miembros de usuarios que emplean un navegador. A continuación, se detallan algunas de las intrusiones típicas en la seguridad que pueden ocurrir:
- Un intruso monitoriza el tráfico de una línea de transmisión y recoge la información confidencial que genera un usuario. Por ejemplo, el intruso podría leer el número, la fecha de caducidad y el nombre del titular de una tarjeta de crédito. Y, a continuación, puede utilizar esta información para realizar pedidos en Internet.
- Un intruso podría entrar en un sistema distribuido, acceder a la base de datos y cambiar la información de la misma. Por ejemplo, podría cambiar el balance de una cuenta en un sistema bancario en la red.
- Un intruso podría leer una transacción que pasa por alguna línea de transmisión y alterar los datos dentro de ella en beneficio propio. Por ejemplo, podría alterar la instrucción de un cliente de un sistema bancario en red para transferir los datos de una cuenta a otra para que la cuenta del intruso sea la que tiene lugar en la transferencia.
- Un ex empleado contrariado de una compañía envía un programa al sistema distribuido de la compañía monopolizando el tiempo del procesador del sistema, pasando gradualmente de servidor a servidor hasta que el sistema queda exhausto y acaba parándose. Esta es una forma de ataque conocido como denegación de ataque al servicio.
- Un empleado contrariado de una compañía envía un programa a un sistema distribuido el cual borra los archivos importantes del sistema.
Estas son entonces algunas de las intrusiones que pueden tener lugar dentro de un sistema distribuido; estas intrusiones cada vez son más frecuentes, ya que gran parte de la transmisión en los sistemas de comercio electrónico ocurren en una Internet públicamente accesible que utiliza protocolos públicamente disponibles. Una de las tareas más importantes del diseñador de sistemas distribuidos es diseñar un sistema con el propósito de minimizar la posibilidad de éxito de las instrucciones de alto riesgo. Para poder llevarlo a cabo se necesita utilizar una serie de tecnologías.
Encriptación
Encriptación es el término que se utiliza para referirse al proceso de transformar datos o texto (texto en claro) para ser ilegible; además, debería resultar virtualmente imposible que un intruso pueda descifrarlo. A continuación, se detalla el proceso de utilización de esta tecnología:
- La computadora emisora transforma el texto en alguna forma ilegible; este proceso se conoce como encriptación.
- Los datos encriptados entonces se envían a través de líneas de transmisión insegura.
- La computadora receptora procesa el texto encriptado y lo transforma a su forma original. Este proceso se conoce como desencriptación.
Se utilizan dos formas de encriptación. La primera es la encriptación simétrica, donde un mensaje se transforma en una forma encriptado utilizando una cadena conocida como clave: se aplica alguna transformación en el mensaje utilizando la clave. Entonces la clave se comunica al receptor a través de algún medio seguro y es utilizado por el receptor para llevar a cabo la desencriptación
La encriptación simétrica es eficiente pero padece un problema importante: si un intruso descubre la clave, podría descubrir fácilmente el mensaje encriptado. La encriptación de clave pública es una solución a este problema, donde se utilizan dos claves de encriptación: una conocida como clave pública y otra como clave privada. Un usuario que desea recibir mensajes encriptados publicará su clave pública. Otros usuarios que deseen comunicarse con el usuario utilizarán esta clave para encriptar cualquier mensaje; los mensajes entonces son desencriptados mediante la clave privada cuando los recibe el usuario original.
Esta forma de encriptación tiene la ventaja principal de que la gestión de claves es sencilla: la clave privada nunca se envía a nadie. Un intruso que monitoriza los datos encriptados que viajan por algún medio de transmisión es incapaz de decodificar ningún mensaje puesto que no tienen acceso posible a la clave privada. El inconveniente principal de esta forma de encriptación es que se necesita una gran cantidad de recursos para llevar a cabo el proceso de desencriptación. Debido a esta clave pública, los sistemas normalmente se limitan a envíos cortos de texto o a un texto pensado para ser altamente seguro. También se utiliza para la autenticación, la cual utiliza una técnica conocida como firmas digitales, que se describen en la sección siguiente.
La tecnología principal que se utiliza en Internet para la encriptación simétrica es la capa de sockets seguros (SSL). Esta es una tecnología que se utiliza para encriptar datos confidenciales tales como los números de las tarjetas de crédito que viajan desde el navegador a un servidor Web, o desde una aplicación a otra.
Funciones de compendio de mensajes
Una función de compendio de mensajes es un algoritmo que genera un número grande -normalmente entre 128 y 256 bits de longitud- que representa un compendio o resumen de los caracteres de un mensaje. Tiene la propiedad de que si el mensaje cambia y se vuelve a aplicar el algoritmo, el número entonces cambia. Existen muchas utilizaciones de las funciones de compendio de mensajes. Un uso común es detectar los cambios en un mensaje, por ejemplo, el hecho de que una transacción financiera se haya modificado en la transmisión con objeto de favorecer al que modifica. Antes de enviar un mensaje se aplica la función de compendio de mensaje y se forma un número grande. El mensaje entonces se envía con el número añadido al final. La función de compendio de mensaje se aplica en el receptor y el número resultante se compara con el que se envió. Si los dos son iguales el mensaje entonces no se ha modificado: si no son iguales el mensaje ha sido modificado durante la transmisión.
Firmas digitales
Una firma digital, como su propio nombre sugiere, es una forma de que el emisor de un mensaje se pueda identificar con el receptor de tal manera que el receptor pueda confiar en que el mensaje fue enviado realmente por el emisor. La encriptación de clave pública es la que se utiliza normalmente para esto. Consideremos una forma de llevar a cabo este proceso: dos usuarios de computadoras A y B quieren comunicarse, y A quiere asegurarse de que se está comunicando con B. Para poder hacer esto, B necesita tener una clave pública y una privada, y tener conocimiento de cuál es la clave pública. A envía un mensaje a B con un texto en el que A pide a B una encriptación utilizando su clave privada. Este texto entonces es encriptado por B y devuelto a A quien lo descifra utilizando la clave pública que B le ha proporcionado. Si el mensaje es el mismo que el que se envió, B es entonces quien dice que es, pero, si no lo es, B entonces no ha demostrado su identidad. Este esquema comparte todas las ventajas de cualquier método de clave pública en donde la clave privada es segura; sin embargo, puede ser atacado por cualquiera que desee establecer falta de confianza entre un emisor y un receptor. Esto se puede hacer alterando el mensaje encriptado que se ha devuelto al emisor.
Certificaciones digitales
Una certificación digital es un documento electrónico que proporciona al usuario un alto de grado de confianza con una organización o persona con la que estén tratando. Se pueden utilizar cuatro tipos de certificaciones: Certificaciones de una autoridad de certificación. Una autoridad de certificación es una organización que proporciona certificados digitales, tales como estas dos organizaciones: Canadá Post Corporation y los servicios postales de US.
Certificaciones del servidor. Estas certificaciones contienen datos tales como la clave pública del servidor, el nombre de la organización que posee el servidor y la dirección del servidor en Internet.
Certificaciones personales. Estas son las certificaciones asociadas a un individuo. Contendrán información física tal como la dirección del individuo junto con la información relacionada con la computadora como la clave pública y la dirección de correo electrónico de la persona.
Certificaciones del editor de software. Estos son certificados que proporcionan confianza en que el software ha sido producido por una compañía de software específica.
Como ejemplo para el funcionamiento de estas certificaciones tomemos el de las certificaciones del servidor. Un servidor que utiliza la capa de sockets seguros (SSL) debe de tener un certificado SSL. Este certificado contiene una clave pública. Cuando un navegador se conecta con el servidor se utiliza entonces esta clave pública para codificar la interacción inicial entre el servidor y el navegador.
- Componentes de software para sistemas C/S
En lugar de visualizar el software como una aplicación monolítica que deberá de implementarse en una máquina, el software que es adecuado para una arquitectura posee varios componentes distintos que se pueden asociar al cliente o al servidor, o se pueden distribuir entre ambas máquinas:
Componente de interacción con el usuario y presentación. Este componente implementa todas las funciones que típicamente se asocian a una interfaz gráfica de usuario (IGU).
Componente de aplicación. Este componente implementa los requisitos definidos en el contexto del dominio en el cual funciona la aplicación. Por ejemplo, una aplicación de negocios podría producir toda una gama de informes impresos basados en entradas numéricas, cálculos, información de una base de datos y otros aspectos. Una aplicación de software de grupo podría proporcionar funciones para hacer posible la comunicación mediante boletines de anuncios electrónicos o de correo electrónico, y en nuestro caso de estudio esto conllevaría la preparación de informes como los que describen las ventas de libros. En ambos casos, el software de la aplicación se puede descomponer de tal modo que alguno de los componentes residan en el cliente y otros residan en el servidor.
Componente de gestión de bases de datos. Este componente lleva a cabo la manipulación y gestión de datos por una aplicación. La manipulación y gestión de datos puede ser tan sencilla como la transferencia de un registro, o tan compleja como el procesamiento de sofisticadas transacciones SQL. Además de estos componentes, existe otro bloque de construcción del software, que suele denominarse software intermedio en todos los sistemas C/S.
Distribución de componentes de software
Una vez que se han determinado los requisitos básicos de una aplicación cliente/servidor, el ingeniero del software debe decidir cómo distribuir los componentes de software entre el cliente y el servidor. Cuando la mayor parte de la funcionalidad asociada a cada uno de los tres componentes se le asocia al servidor, se ha creado un diseño de servidor pesado (grueso). A la inversa, cuando el cliente implementa la mayor parte de los componentes de interacción/presentación con el usuario, de aplicación y de bases de datos, se tiene un diseño de cliente pesado (grueso).
Los clientes pesados suelen encontrarse cuando se implementan arquitecturas de servidor de archivo y de servidor de base de datos. En este caso el servidor proporciona apoyo para la gestión de datos, pero todo el software de aplicación y de IGU reside en el cliente. Los servidores pesados son los que suelen diseñarse cuando se implementan sistemas de transacciones y de trabajo en grupo. El servidor proporciona el apoyo de la aplicación necesario para responder a transacciones y comunicaciones que provengan de los clientes. El software de cliente se centra en la gestión de IGU y de comunicación.
Se pueden utilizar clientes y servidores pesados para ilustrar el enfoque general de asignación de componentes de software de cliente-servidor. Sin embargo, un enfoque más granular para la asignación de componentes de software define cinco configuraciones diferentes.
Presentación distribuida. En este enfoque cliente-servidor rudimentario, la lógica de la base de datos y la lógica de la aplicación permanecen en el servidor, típicamente en una computadora central. El servidor contiene también la lógica para preparar información de pantalla, empleando un software tal como CICS. Se utiliza un software especial basado en PC para transformar la información de pantalla basada en caracteres que se transmite desde el servidor en una presentación IGU en un PC.
Presentación remota. En esta extensión del enfoque de presentación distribuida, la lógica primaria de la base de datos y de la aplicación permanecen en el servidor, y los datos enviados por el servidor serán utilizados por el cliente para preparar la presentación del usuario.
Lógica distribuida. Se asignan al cliente todas las tareas de presentación del usuario y también los procesos asociados a la introducción de datos tales como la validación de nivel de campo, la formulación de consultas de servidor y las solicitudes de informaciones de actualizaciones del servidor. Se asignan al servidor las tareas de gestión de las bases de datos, y los procesos para las consultas del cliente, para actualizaciones de archivos del servidor, para control de versión de clientes y para aplicaciones de ámbito general de la empresa.
Gestión de datos remota. Las aplicaciones del servidor crean una nueva fuente de datos dando formato a los datos que se han extraído de algún otro lugar (por ejemplo, de una fuente de nivel corporativo). Las aplicaciones asignadas al cliente se utilizan para explotar los nuevos datos a los que se ha dado formato mediante el servidor. En esta categoría se incluyen los sistemas de apoyo de decisiones.
Bases de datos distribuidas. Los datos de que consta la base de datos se distribuyen entre múltiples clientes y servidores. Consiguientemente, el cliente debe de admitir componentes de software de gestión de datos así como componentes de aplicación y de IGU.
Durante los Últimos años se ha dado mucha importancia a la tecnología de cliente ligero. Un cliente ligero es la llamada «computadora de redes» que relega todo el procesamiento de la aplicación a un servidor pesado. Los clientes ligeros (computadoras de red) ofrecen un coste por unidad sustancialmente más bajo a una pérdida de rendimiento pequeña o nada significativa en comparación con las computadoras de sobremesa.
Líneas generales para la distribución de componentes de aplicaciones
Aun cuando no existen reglas absolutas que describan la distribución de componentes de aplicaciones entre el cliente y el servidor, suelen seguirse las siguientes líneas generales:
El componente de presentación-interacción suele ubicarse en el diente. La disponibilidad de entornos basados en ventanas y de la potencia de cómputo necesaria para una interfaz gráfica de usuario hace que este enfoque sea eficiente en términos de coste.
Si es necesario compartir la base de datos entre múltiples usuarios conectados a través de la LAN, entonces la base de datos suele ubicarse en el servidor. El sistema de gestión de la base de datos y la capacidad de acceso a la base de datos también se asigna al servidor, junto con la base de datos física.
Los datos estáticos que se utilicen deberían de asignarse al cliente. Esto sitúa los datos más próximos al usuario que tiene necesidad de ellos y minimiza un tráfico de red innecesario y la carga del servidor.
El resto de los componentes de la aplicación se distribuye entre cliente y servidor basándose en la distribución que optimice las configuraciones de cliente y servidor y de la red que los conecta. Por ejemplo, la implementación de una relación mutuamente excluyente implica una búsqueda en la base de datos para determinar si existe un registro que satisfaga los parámetros de una cierta trama de búsqueda. Si no se encuentra ningún registro, se emplea una trama de búsqueda alterativa. Si la aplicación que controla esta trama de búsqueda está contenida en su totalidad en el servidor, se minimiza el tráfico de red. La primera transmisión de la red desde el cliente hacia el servidor contendría los parámetros tanto para la trama de búsqueda primaria como para la trama de búsqueda secundaria. La lógica de aplicación del servidor determinaría si se requiere la segunda búsqueda. El mensaje de repuesta al cliente contendría el registro hallado como consecuencia bien de la primera o bien de la segunda búsqueda. El enfoque alternativo (el cliente implementa la lógica para determinar si se requiere una segunda búsqueda) implicaría un mensaje para la primera recuperación de registros, una respuesta a través de la red si no se halla el registro, un segundo mensaje que contuviera los parámetros de la segunda búsqueda, y una respuesta final que contuviera el registro recuperado. Si en la segunda búsqueda se necesita el 50 por 100 de las veces, la colocación de la lógica en el servidor para evaluar la primera búsqueda e iniciar la segunda si fuera necesario reduciría el tráfico de red en
Un 33 por 100.
La decisión final acerca de la distribución de componentes debería estar basada no solamente en la aplicación individual, sino en la mezcla de aplicaciones que esté funcionando en el sistema. Por ejemplo, una instalación podría contener algunas aplicaciones que requieran un extenso procesamiento de IGU y muy poco procesamiento central de la base de datos. Esto daría lugar a la utilización de potentes estaciones de trabajo en el lado cliente y a un servidor muy sencillo. Una vez implantada esta configuración, otras aplicaciones favorecerían el enfoque de cliente principal, para que las capacidades del servidor no tuvieran necesidad de verse aumentadas.
Habría que tener en cuenta que a medida que madura el uso de la arquitectura cliente/servidor, la tendencia es a ubicar la lógica de la aplicación volátil en el servidor. Esto simplifica la implantación de actualizaciones de software cuando se hacen cambios en la lógica de la aplicación.
Enlazado de componentes de software C/S
Se utiliza toda una gama de mecanismos distintos para enlazar los distintos componentes de la arquitectura cliente-servidor. Estos mecanismos están incluidos en la estructura de la red y del sistema operativo, y resultan transparentes para el usuario final situado en el centro cliente. Los tipos más comunes de mecanismos de enlazado son:
- Tuberías (pipes): se utilizan mucho en los sistemas basados en UNIX; las tuberías permiten la mensajería entre distintas máquinas que funcionen con distintos sistemas operativos.
- Llamadas a procedimientos remotos: permiten que un proceso invoque la ejecución de otro proceso o módulo que resida en una máquina distinta.
- Interacción SQL cliente-servidor: se utiliza para pasar solicitudes SQL y datos asociados de un componente (típicamente situado en el cliente) a otro componente (típicamente el SGBD del servidor). Este mecanismo está limitado únicamente a las aplicaciones SGBDR. Conexiones (sockets).
Software intermedio (middleware) y arquitecturas de agentes de solicitud de objetos
Los componentes de software C/S están implementados mediante objetos que deben de ser capaces de interactuar entre sí en el seno de una sola máquina (bien sea cliente o servidor) o a través de la red. Un agente de distribución de objetos (ORB) es un componente de software intermedio que capacita a un objeto que resida en un cliente para enviar un mensaje a un método que esté encapsulado en otro objeto que resida en un servidor. En esencia, el ORB intercepta el mensaje y maneja todas las actividades de comunicación y de coordinación necesarias para hallar el objeto al cual se había destinado el mensaje, para invocar su método, para pasar al objeto los datos adecuados, y para transferir los datos resultantes de vuelta al objeto que generase el mensaje inicialmente.
En la Figura 28.6 se muestra la estructura básica de una arquitectura CORBA. Cuando se implementa CORBA en un sistema cliente-servidor, los objetos y las clases de objetos tanto en el cliente como en el servidor se definen utilizando un lenguaje de descripción de interfaces (LDI’), un lenguaje declarativo que permite que el ingeniero del software defina objetos, atributos, métodos y los mensajes que se requieren para invocarlos. Con objeto de admitir una solicitud para un método residente en el servidor procedente de un objeto residente en el cliente, se crean stubs LDI en el cliente y en el servidor. Estos stubs proporcionan la pasarela a través de la cual se admiten las solicitudes de objetos a través del sistema C/S. Dado que las solicitudes de objetos a través de la red se producen en el momento de la ejecución, es preciso establecer un mecanismo para almacenar una descripción del objeto de tal modo que la información pertinente acerca del objeto y de su ubicación esté disponible cuando sea necesario. El repositorio de interfaz hace precisamente esto.
Cuando una aplicación cliente necesita invocar un método contenido en el seno de un objeto residente en alguna otra parte del sistema, CORBA utiliza una invocación dinámica para
- obtener la información pertinente acerca del objeto deseado a partir del depósito de interfaz.
- crear una estructura de datos con parámetros que habrá que pasar al objeto.
- crear una solicitud para el objeto.
- invocar la solicitud.
A continuación, se pasa la solicitud al núcleo ORB –una parte dependiente de implementación del sistema operativo en red que gestione las solicitudes- y, a continuación, se satisface la solicitud.
La solicitud se pasa a través del núcleo y es procesada por el servidor. En la ubicación del servidor, un adaptador de objetos almacena la información de clases y de objetos en un depósito de interfaz residente en el servidor, admite y gestiona las solicitudes procedentes del cliente, y lleva a cabo otras muchas tareas de gestión de objetos. En el servidor unos stubs LDI, similares a los definidos en la máquina cliente, se emplean como interfaz con la implementación del objeto real que reside en la ubicación del servidor. El desarrollo del software para sistemas C/S modernos está orientado a objetos. Empleando la arquitectura CORBA descrita brevemente en esta sección, los desarrolladores de software pueden crear un entorno en el cual se pueden reutilizar los objetos a lo largo y ancho de una red muy amplia.
- Ingeniería de software para sistemas C/S
Aun cuando muchos de ellos se podrían adaptar para su utilización en el desarrollo de software para sistemas C/S, hay dos enfoques que son los que se utilizan más comúnmente:
- Un paradigma evolutivo que hace uso de la ingeniería del software basada en sucesos y/o orientada a objetos.
- una ingeniería del software basada en componentes que se basa en una biblioteca de componentes de software CYD y de desarrollo propio.
Los sistemas cliente servidor se desarrollan empleando las actividades de ingeniería del software clásico el análisis, diseño, construcción y depuración- a medida que evoluciona el sistema a partir de un conjunto de requisitos de negocios generales para llegar a ser una colección de componentes de software ya validados que han sido implementados en máquinas cliente y servidor.

- Problemas de modelados de análisis
La actividad de modelado de requisitos para los sistemas C/S difiere poco de los métodos de modelado de análisis que se aplicaban para la arquitectura de computadoras más convencionales. Se debería destacar, sin embargo, que dado que muchos sistemas C/S modernos hacen uso de componentes reutilizables, también se aplican las actividades de cualificación asociadas a la ISBC. Dado que el modelado de análisis evita la especificación de detalles de implementación, sólo cuando se haga la transición al diseño se considerarán los problemas asociados a la asignación de software al cliente y al servidor3. Sin embargo, dado que se aplica un enfoque evolutivo de la ingeniería del software para los sistemas C/S, las decisiones de implementación acerca del enfoque C/S global (por ejemplo, cliente pesado frente a servidor pesado) se podrán hacer durante las primeras iteraciones de análisis y diseño.
- Diseño de sistemas C/S
Cuando se está desarrollando un software para su implementación empleando una arquitectura de computadoras concreta, el enfoque de diseño debe de considerar el entorno específico de construcción. En esencia, el diseño debería de personalizarse para adecuarlo a la arquitectura del hardware. Cuando se diseña software para su implementación empleando una arquitectura
cliente-servidor, el enfoque de diseño debe de ser «personalizado» para adecuarlo a los problemas siguientes:
- El diseño de datos domina el proceso de diseño. Para utilizar efectivamente las capacidades de un sistema de gestión de bases de datos relacional (SGBDR) o un sistema de gestión de bases de datos orientado a objetos (SGBDOO) el diseño de los datos pasa a ser todavía más significativo que en las aplicaciones convencionales.
- Cuando se selecciona el paradigma controlado por sucesos, debería realizarse el modelado del comportamiento y será preciso traducir los aspectos orientados al control implícitos en el modelo de comportamiento al modelo de diseño.
- El componente de interacción/presentación del usuario de un sistema C/S implementa todas aquellas funciones que se asocian típicamente con una interfaz gráfica de usuario (IGU). Consiguientemente, se verá incrementada la importancia del diseño de interfaces. El componente de interacción/presentación del usuario implementa todas las funciones que se asocian típicamente con una interfaz gráfica de usuario (IGU).
- Suele seleccionarse un punto de vista orientado a objetos para el diseño. En lugar de la estructura secuencia1 que proporciona un lenguaje de procedimientos se proporciona una estructura de objetos mediante la vinculación entre los sucesos iniciados en la IGU y una función de gestión de sucesos que reside en el software basado en el cliente.
Diseño arquitectónico para sistemas cliente/servidor
El diseño arquitectónico de un sistema cliente servidor se suele caracterizar como un estilo de comunicación de procesos. Bass y sus colegas describe esta arquitectura de la siguiente manera:
El objetivo es lograr la calidad de la escalabilidad. Un servidor existe para proporcionar datos para uno o más clientes, que suelen estar distribuidos en una red. El cliente origina una llamada al servidor, el cual trabaja síncronamente o asíncronamente, para servir a la solicitud del cliente. Si el servidor funciona síncronamente, devuelve el control al cliente al mismo tiempo que devuelve los datos. Si el servidor trabaja asíncronamente, devuelve solo los datos al cliente (el que tiene su propio hilo de control).
Dado que los sistemas modernos C/S están basados en componentes, se utiliza una arquitectura de agente de solicitud de objetos (ORB) para implementar esta comunicación síncrona y asíncrona. A un nivel arquitectónico, el lenguaje de descripción de la interfaz CORBA4 se utiliza para especificar los detalles de la interfaz. La utilización de LDI permite que los componentes de software de la aplicación accedan a los servicios ORB (componentes) sin un conocimiento de su funcionamiento interno. El ORB también tiene la responsabilidad de coordinar la comunicación entre los componentes del cliente y del servidor. Para lograr esto, el diseñador especifica un adaptador de objetos (también llamado encubridor) que proporciona los servicios siguientes:
- Se registran las implementaciones de componentes (objetos).
- Se interpretan y se reconcilian todas las referencias de componentes (objetos).
- Se hacen coincidir las referencias de componentes (objetos) con la implementación de los componentes correspondiente.
- Se activan y desactivan objetos.
- Se invocan métodos cuando se transmiten mensajes.
- Se implementan servicios de seguridad.
Para admitir los componentes CYD proporcionados por proveedores diferentes y componentes de desarrollo propio que pueden haber sido implementados utilizando diferentes tecnologías, se debe diseñar la arquitectura ORB para lograr interoperabilidad entre componentes. Para poderlo llevar a cabo CORBA utiliza un concepto puente. Supongamos que un cliente se haya implementado utilizando un protocolo ORB X y que el servidor se haya implementado utilizando el protocolo ORB Y. Ambos protocolos son conforme CORBA, pero debido a las diferencias de implementación internas, se deben comunicar con un «puente» que proporcione un mecanismo para la traducción entre protocolos internos. El puente traduce mensajes de manera que el cliente y el servidor se puedan comunicar suavemente.
Enfoques de diseño convencionales para software de aplicaciones
En los sistemas cliente/servidor, los diagramas de flujo se pueden utilizar para establecer el ámbito del sistema, para identificar las funciones de nivel superior y las áreas de datos temáticas (almacenes de datos), y para permitir la descomposición de funciones de nivel superior. Apartándose del enfoque DFD tradicional, sin embargo, la descomposición se detiene en el nivel de un proceso de negocio elemental, en lugar de proseguir hasta el nivel de procesos atómicos. En el contexto C/S, se puede definir un proceso elemental de negocios (PEN) como un cierto conjunto de tareas que se llevan a cabo sin interrupción por parte de un usuario en los centros cliente. Estas tareas o bien se realizan en su totalidad, o bien no se realizan en absoluto.
El diagrama entidad relación adopta también un papel más importante. Sigue utilizándose para descomponer las áreas de datos temáticas (de almacenes de datos) de los DFD con objeto de establecer una visión de alto nivel de la base de datos que haya que implementar empleando un SGBDR. Su nuevo papel consiste en proporcionar la estructura para definir objetos de negocios de alto nivel. En lugar de servir como herramientas para una descomposición funcional, el diagrama de estructuras se utiliza ahora como diagrama de ensamblaje, con objeto de mostrar los componentes implicados en la solución de algún procedimiento de negocios elemental. Estos componentes, que constan de objetos de interfaz, objetos de aplicación y objetos de bases de datos, establecen la forma en la que se van a procesar los datos.
Diseño de bases de datos
El diseño de bases de datos se utiliza para definir y después para especificar la estructura de los objetos de negocios que se emplean en el sistema cliente/servidor. El análisis necesario para identificar los objetos de negocios se lleva a cabo empleando los métodos de ingeniería de la información. La notación de modelado del análisis convencional, tal como DER, se podrá utilizar para definir objetos de negocios, pero es preciso establecer un depósito de base de datos para capturar la información adicional que no se puede documentar por completo empleando una notación gráfica tal como un DER.
En este depósito, se define un objeto de negocio como una información que es visible para los compradores y usuarios del sistema, pero no para quienes lo implementan, por ejemplo, un libro en el caso de estudio de ventas de libros. Esta información que se implementa utilizando una base de datos relacional, se puede mantener en un depósito de diseño. La siguiente información de diseño se recoge para la base de datos cliente-servidor:
- Entidades: se identifican en el DER del nuevo sistema.
- Archivos: que implementan las entidades identificadas en el DER.
- Relación entre campo y archivo: establece la disposición de los archivos al identificar los campos que están incluidos en cada archivo.
- Campos: define los campos del diseño (el diccionario de datos).
- Relaciones entre archivos: identifican los archivos relacionados que se pueden unir para crear vistas lógicas o consultas.
- Validación de relaciones: identifica el tipo de relaciones entre archivos o entre archivos y campos que se utilicen par la validación.
- Tipos de campo: se utiliza para permitir la herencia de características de campos procedentes de superenlaces del campo (por ejemplo, fecha, texto, número, valor, precio).
- Tipo de datos: las características de los datos contenidos en el campo.
- Tipo de archivo: se utiliza para identificar cualquiera de las ubicaciones del archivo.
- Función del campo: clave, clave externa, atributo, campo virtual, campo derivado, etc.
- Valores permitidos: identifica los valores permitidos para los campos de tipo de estado.
- Reglas de negocios: reglas para editar, calcular campos derivados, etc.
A medida que las arquitecturas C/S se han ido haciendo más frecuentes, la tendencia hacia una gestión de datos distribuida se ha visto acelerada. En los sistemas C/S que implementan este enfoque, el componente de gestión de datos reside tanto en el cliente como en el servidor. En el contexto del diseño de bases de datos, un problema fundamental es la distribución de datos. Esto es, cómo se distribuyen los datos entre el cliente y el servidor y cómo se dispersan entre los nudos de la red? Un sistema de gestión de bases de datos relaciona1 (SGBDR) hace fácil el acceso a datos distribuidos mediante el uso del lenguaje de consulta estructurado (SQL). La ventaja de SQL en una estructura C/S es que «no requiere navegar» [BER92]. En un SGBDR, los tipos de datos se especifican empleando SQL, pero no se requiere información de navegación. Por supuesto, la implicación de esto es que SGBDR debe ser suficientemente sofisticado para mantener la ubicación de todos los datos y tiene que ser capaz de definir la mejor ruta hasta ella. En sistemas de bases de datos menos sofisticados, una solicitud de datos debe indicar a qué hay que acceder y dónde se encuentra. Si el software de aplicación debe mantener la información de navegación, entonces la gestión de datos se vuelve mucho más complicada por los sistemas C/S.
Es preciso tener en cuenta que también están disponibles para el diseñador otras técnicas para la distribución y gestión de datos:
Extracción manual. Se permite al usuario copiar manualmente los datos adecuados de un servidor a un cliente. Este enfoque resulta útil cuando el usuario requiere unos datos estáticos y cuando se puede dejar el control de la estación en manos del usuario.
Instantánea. Esta técnica automatiza la extracción manual al especificar una «instantánea» de los datos que deberán de transferirse desde un cliente hasta un servidor a intervalos predefinidos. Este enfoque es Útil para distribuir unos datos relativamente estáticos que solamente requieran actualizaciones infrecuentes.
Duplicación. Se puede utilizar esta técnica cuando es preciso mantener múltiples copias de los datos en distintos lugares (por ejemplo, servidores distintos o clientes y servidores). En este caso, el nivel de complejidad se incrementa porque la consistencia de los datos, las actualizaciones, la seguridad y el procesamiento deben de coordinarse entre los múltiples lugares.
Fragmentación. En este enfoque, la base de datos del sistema se fragmenta entre múltiples máquinas. Aunque resulta intrigante en teoría, la fragmentación es excepcionalmente difícil de implementar y hasta el momento no es frecuente encontrarla.
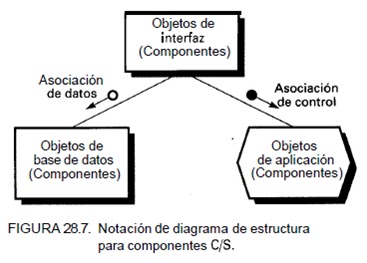
Visión general de un enfoque de diseño
Porter sugiere un conjunto de pasos para diseñar un proceso elemental de negocio que combine elementos de diseño convencional con elementos de diseño orientado a objetos. Se supone que se ha desarrollado un modelo de requisitos que defina los objetos de negocio, y que se ha refinado ya antes de comenzar el diseño de los procesos elementales de negocio. Entonces, se utilizan los pasos siguientes para derivar el diseño:
- Para cada proceso elemental de negocio, se identifican los archivos creados, actualizados, borrados o referenciados
- Se utilizan los archivos identificados en el paso 1 como base para definir componentes u objetos.
- Para cada componente, se recuperan las reglas de negocio y otra información de objetos de negocio que se haya determinado para el archivo relevante.
- Se determinan las reglas que son relevantes para el proceso y se descomponen las reglas hasta llegar al nivel de métodos.
- Según sea necesario, se definen los componentes adicionales que se requieren para implementar los métodos.
Porter sugiere una notación especializada de diagramas de estructura (Fig. 28.7) para representar la estructura de componentes de un proceso elemental de negocio. Sin embargo, se utiliza una simbología diferente para que el diagrama se ajuste a la naturaleza orientada a objetos del software C/S. En la figura, se encuentran cinco símbolos distintos:
Objeto de interfaz. Este tipo de componente, que también se denomina componente de interacción/presentación con el usuario, se construye típicamente en un único archivo o bien otros archivos relacionados que se hayan unido mediante una consulta. Incluye métodos para dar formato a la interfaz IGU y también la lógica de aplicación residente en el cliente, junto con los controles de la interfaz. También incluye sentencias incrustadas de SQL, que especifican el procesamiento de la base de datos efectuado en el archivo primario con respecto al cual se haya construido la interfaz. Si la lógica de aplicación asociada normalmente a un objeto de interfaz se implementa en un servidor, típicamente mediante el uso de herramientas de software intermedio, entonces la lógica de aplicación que funcione en el servidor deberá de identificarse como un objeto de aplicación por separado.
Objeto de base de datos. Este tipo de componentes se utiliza para identificar el procesamiento de bases de datos tal como la creación o selección de registros que esté basada en un archivo distinto del archivo primario en el cual se haya construido el objeto de interfaz. Es preciso tener en cuenta que si el archivo primario con respecto al cual se construye el objeto de interfaz se procesa de manera distinta, entonces se puede utilizar un segundo conjunto de sentencias SQL para recuperar un archivo en una secuencia alternativa. La técnica de procesamiento del segundo archivo debería identificarse por separado en el diagrama de estructura, en forma de un objeto de base de datos por separado.
Objeto de aplicación. Es utilizado por un objeto de interfaz, bien por un objeto de base de datos, y este componente será invocado bien por un activador de una base de datos, o por una llamada a procedimientos remotos. También se puede emplear para identificar la lógica de negocios que normalmente se asocia al procesamiento de interfaz que ha sido trasladado al servidor para su funcionamiento.
Asociación de datos. Cuando un objeto invoca a otro objeto independiente, se pasa un mensaje entre dos objetos. El símbolo de asociación de datos se utiliza para denotar este hecho.
Asociación de control. Cuando un objeto invoca a otro objeto independiente y no se pasan entre los dos objetos, se utiliza un símbolo de asociación de control.
Iteración de diseño de procesos
El repositorio de diseño, que se utiliza para representar objetos de negocio, se emplea también para representar objetos de interfaz, de aplicación y de base de datos. Obsérvese que se han identificado las entidades siguientes:
Métodos: describen cómo hay que implementar una regla de negocio.
Procesos elementales: definen los procesos elementales de negocio identificados en el modelo de análisis.
Enlace proceso/componente: identifica a los componentes que forman la solución de un proceso elemental de negocio.
Componentes: describe los componentes mostrados en el diagrama de estructura.
Enlace regla de negocios/cornponente: identifican a los componentes que son significativos para la implementación de una determinada regla de negocio.
Si se implementa un repositorio utilizando un SGBDR, el diseñador tendrá acceso a una herramienta de diseño muy Útil que proporciona informes que sirven de ayuda tanto para la construcción como para el futuro mantenimiento del sistema C/S.
- Problemas de las pruebas
La naturaleza distribuida de los sistemas cliente-servidor plantea un conjunto de problemas específicos para los probadores de software. Binder sugiere las siguientes zonas de interés:
- Consideraciones del IGU de cliente
- Consideraciones del entorno destinado y de la diversidad de plataformas
- Consideraciones de bases de datos distribuidas (incluyendo datos duplicados)
- Consideraciones de procesos distribuidos (incluyendo procesos duplicados)
- Entornos destino que no son robustos
- Relaciones de rendimiento no lineales
Estrategia general de prueba C/S
En general, las pruebas de software cliente/servidor se produce en tres niveles diferentes:
- las aplicaciones de cliente individuales se prueban de modo <desconectado> (el funcionamiento del servidor y de la red subyacente no se consideran.
- las aplicaciones de software de cliente y del servidor asociado se prueban al unísono, pero no se ejercitan específicamente las operaciones de red.
- se prueba la arquitectura completa de C/S, incluyendo el rendimiento y funcionamiento de la red.
Aun cuando se efectúen muchas clases distintas de pruebas en cada uno de los niveles de detalle anteriores, es frecuente encontrar los siguientes enfoques de pruebas para aplicaciones C/S:
Pruebas de función de aplicación. Se prueba la funcionalidad de las aplicaciones cliente utilizando los métodos. En esencia, la aplicación se prueba en solitario en un intento de descubrir errores de su funcionamiento.
Pruebas de servidor. Se prueban la coordinación y las funciones de gestión de datos del servidor. También se considera el rendimiento del servidor (tiempo de respuesta y trasvase de datos en general).
Pruebas de bases de datos. Se prueba la precisión e integridad de los datos almacenados en el servidor. Se examinan las transacciones enviadas por las aplicaciones cliente para asegurar que los datos se almacenen, actualicen y recuperen adecuadamente. También se prueba el archivado.
Pruebas de transacciones. Se crea una serie de pruebas adecuada para comprobar que todas las clases de transacciones se procesen de acuerdo con los requisitos. Las transacciones hacen especial hincapié en la corrección de procesamiento y también en los temas de rendimiento (por ejemplo, tiempo de procesamiento de transacciones y comprobación de volúmenes de transacciones).
Pruebas de comunicaciones a través de la red. Estas pruebas verifican que la comunicación entre los nudos de la red se produzca correctamente, y que el paso de mensaje, las transacciones y el tráfico de red relacionado tenga lugar sin errores. También se pueden efectuar pruebas de seguridad de la red como parte de esta actividad de prueba.
Para llevar a cabo estos enfoques de pruebas, Musa recomienda el desarrollo de perfiles operativos derivados de escenarios cliente/servidor. Un perfil operativo indica la forma en que los distintos tipos de usuarios interactúan con el sistema C/S. Esto es, los perfiles proporcionan un «patrón de USO» que se puede aplicar cuando se diseñan y ejecutan las pruebas. Por ejemplo, para un determinado tipo de usuarios, ¿qué porcentaje de las transacciones serán consultas? ¿Actualizaciones? ¿Pedidos?
Para desarrollar el perfil operativo, es preciso derivar un conjunto de escenarios de usuario, que sea similar a los casos prácticos de estudio tratados en este libro. Cada escenario abarca quién, dónde, qué y por qué. Esto es, quién es el usuario, dónde (en la arquitectura física) se produce la interacción con el sistema, cuál es la transacción, y por qué ha sucedido. Se pueden derivar los escenarios durante las técnicas de obtención de requisitos o a través de discusiones menos formales con los usuarios finales. Sin embargo, el resultado debería ser el mismo. Cada escenario debe proporcionar una indicación de las funciones del sistema que se necesitarán para dar servicio a un usuario concreto; el orden en que serán necesarios esas funciones, los tiempos y respuestas que se esperan, y la frecuencia con la que se utilizará cada una de estas funciones. Entonces se combinan estos datos (para todos los usuarios) para crear el perfil operativo.
La estrategia para probar arquitecturas C/S es análoga a la estrategia de pruebas para sistemas basados en software. La comprobación comienza por comprobar al por menor. Esto es, se comprueba una única aplicación de cliente. La integración de los clientes, del servidor y de la red se irá probando progresivamente. Finalmente, se prueba todo el sistema como entidad operativa. La prueba tradicional visualiza la integración de módulos para subsistemas/sistemas y su prueba como un proceso descendente, ascendente o alguna variación de los dos anteriores. La integración de módulos en el desarrollo C/S puede tener algunos aspectos ascendentes o descendentes, pero la integración en proyectos C/S tiende más hacia el desarrollo paralelo y hacia la integración de módulos en todos los niveles de diseño. Por tanto, la prueba de integración en proyectos C/S se efectúa a veces del mejor modo posible empleando una aproximación no incremental o del tipo «big bang».
El hecho de que el sistema no se esté construyendo para utilizar un hardware y un software especificado con anterioridad tiene su impacto sobre la comprobación del sistema. La naturaleza multiplataforma en red de los sistemas C/S requiere que se preste bastante más atención a la prueba de configuraciones y a la prueba de compatibilidades.
La doctrina de prueba de configuraciones impone la prueba del sistema en todos los entornos conocidos de hardware y software en los cuales vaya a funcionar. La prueba de compatibilidad asegura una interfaz funcionalmente consistente entre plataformas de software y hardware. Por ejemplo, la interfaz de ventanas puede ser visualmente distinta dependiendo del entorno de implementación, pero los mismos comportamientos básicos del usuario deberían dar lugar a los mismos resultados independientemente del estándar de interfaz de cliente.
Táctica de pruebas C/S
Aun cuando el sistema C/S no se haya implementado empleando tecnología orientada a objetos, las técnicas de pruebas orientadas a objetos tienen sentido porque los datos y procesos duplicados se pueden organizar en clases de objetos que compartan un mismo conjunto de propiedades. Una vez que se hayan derivado los casos prácticos para una clase de objetos (o su equivalente en un sistema desarrollado convencionalmente), estos casos de prueba deberían resultar aplicables en general a todas las instancias de esa clase.
El punto de vista O0 es especialmente valioso cuando se considera la interfaz gráfica de usuario de los sistemas C/S modernos. La IGU es inherentemente orientada a objetos, y se aparta de las interfaces tradicionales porque tiene que funcionar en muchas plataformas. Además, la comprobación debe explorar un elevado número de rutas lógicas, porque la IGU crea, manipula y modifica una amplia gama de objetos gráficos. La comprobación se ve complicada aun más porque los objetos pueden estar presentes o ausentes, pueden existir durante un cierto período de tiempo, y pueden aparecer en cualquier lugar del escritorio. Esto significa que el enfoque tradicional de captura/ reproducción para comprobar interfaces convencionales basadas en caracteres debe ser modificado para que pueda manejar las complejidades de un entorno IGU. Ha aparecido una variación funcional del paradigma de captura/reproducción denominado captura1 reproducción estructurada para efectuar la prueba de la IGU.
La captura/reproducción tradicional registra las entradas tales como las teclas pulsadas y las salidas tales como imágenes de pantalla que se almacenan para comprobaciones posteriores. La captura/reproducción estructurada está basada en una visión interna (lógica) de las actividades externas. Las interacciones del programa de aplicación con la IGU se registran como sucesos internos, que se pueden almacenar en forma de «guiones» escritos en Visual Basic de Microsoft, en una de las variantes de C, o en el lenguaje patentado del fabricante. Las herramientas que ejercitan las IGUs no abarcan las validaciones de datos tradicionales ni tampoco las necesidades de comprobación de rutas. Los métodos de comprobación de caja blanca y caja negra son aplicables en muchos casos, y las estrategias orientadas a objetos especiales son adecuadas tanto para el software de cliente como para el software de servidor.
Bibliografía:
Pressman .S. Roger. Ingeniería de Software. Un enfoque practico. Editorial McGraw-Hill V Edición. Pág. 491-518
0 comentarios:
Publicar un comentario